

A meta robots tag is a bit of HTML code that tells search engine robots the best way to crawl, index, and show a web page’s content material.
It goes within the
part of the web page and might appear to be this:
The meta robots tag within the instance above tells all search engine crawlers to not index the web page.
Let’s focus on what you should utilize robots meta tags for, why they’re necessary for search engine marketing, and the best way to use them correctly.
Meta robots tags and robots.txt recordsdata have comparable capabilities however serve totally different functions.
A robots.txt file is a single textual content file that applies to your entire web site. And tells engines like google which pages to crawl.
A meta robotstag applies to solely the web page containing the tag. And tells engines like google the best way to crawl, index, and show data from that web page solely.
Robots meta tags assist management how Google crawls and indexes a web page’s content material. Together with whether or not to:
- Embrace a web page in search outcomes
- Follow the links on a web page
- Index the photographs on a web page
- Present cached outcomes of the web page on the search engine outcomes pages (SERPs)
- Present a snippet of the web page on the SERPs
Under, we’ll discover the attributes you should utilize to inform engines like google the best way to work together together with your pages.
However first, let’s focus on why robots meta tags are necessary and the way they will have an effect on your web site’s search engine marketing.
Robots meta tags assist Google and different engines like google crawl and index your pages effectively.
Particularly for big or ceaselessly up to date websites.
In any case, you seemingly don’t want each web page in your web site to rank.
For instance, you in all probability don’t need engines like google to index:
- Pages out of your staging web site
- Affirmation pages, comparable to thanks pages
- Admin or login pages
- Inside search end result pages
- Pages with duplicate content
Combining robots meta tags with different directives and recordsdata, comparable to sitemaps and robots.txt, can subsequently be a helpful a part of your technical SEO technique. As they can assist forestall points that might in any other case maintain again your web site’s efficiency.
What Are the Title and Content material Specs for Meta Robots Tags?
Meta robots tags comprise two attributes: identify and content material. Each are required.
Title Attribute
This attribute signifies which crawler ought to observe the directions within the tag.
Like this:
identify="crawler"
If you wish to tackle all crawlers, insert “robots” because the “identify” attribute.
Like this:
identify="robots"
If you wish to limit crawling to particular engines like google, the identify attribute allows you to do this. And you’ll select as many (or as few) as you need.
Listed here are a number of widespread crawlers:
- Google: Googlebot (or Googlebot-news for information outcomes)
- Bing: Bingbot (see the list of all Bing crawlers)
- DuckDuckGo: DuckDuckBot
- Baidu: Baiduspider
- Yandex: YandexBot
Content material Attribute
The “content material” attribute comprises directions for the crawler.
It seems like this:
content material="instruction"
Google helps the next “content material” values:
Default Content material Values
With no robots meta tag, crawlers will index content material and observe hyperlinks by default (until the hyperlink itself has a “nofollow” tag).
This is identical as including the next “all” worth (though there isn’t any have to specify it):
So, when you don’t need the web page to look in search outcomes or for engines like google to crawl its hyperlinks, you might want to add a meta robots tag. With correct content material values.
Noindex
The meta robots “noindex” worth tells crawlers to not embrace the web page within the search engine’s index or show it within the SERPs.
With out the noindex worth, engines like google could index and serve the web page within the search outcomes.
Typical use circumstances for “noindex” are cart or checkout pages on an ecommerce web site.
Nofollow
This tells crawlers to not crawl the hyperlinks on the web page.
Google and different engines like google usually use hyperlinks on pages to find these linked pages. And hyperlinks can assist cross authority from one web page to a different.
Use the nofollow rule when you don’t need the crawler to observe any hyperlinks on the web page or cross any authority to them.
This could be the case when you don’t have management over the hyperlinks positioned in your web site. Equivalent to in an unmoderated discussion board with largely user-generated content material.
Noarchive
The “noarchive” content material worth tells Google to not serve a duplicate of your web page within the search outcomes.
For those who don’t specify this worth, Google could present a cached copy of your web page that searchers might even see within the SERPs.
You could possibly use this worth for time-sensitive content material, inner paperwork, PPC touchdown pages, or some other web page you don’t need Google to cache.
Noimageindex
This worth instructs Google to not index the photographs on the web page.
Utilizing “noimageindex” might damage potential organic traffic from picture outcomes. And if customers can nonetheless entry the web page, they’ll nonetheless be capable of discover the photographs. Even with this tag in place.
Notranslate
“Notranslate” prevents Google from serving translations of the web page in search outcomes.
For those who don’t specify this worth, Google can present a translation of the title and snippet of a search end result for pages that aren’t in the identical language because the search question.
If the searcher clicks the translated hyperlink, all additional interplay is thru Google Translate. Which routinely interprets any adopted hyperlinks.
Use this worth when you desire to not have your web page translated by Google Translate.
For instance, in case you have a product web page with product names you don’t need translated. Or when you discover Google’s translations aren’t at all times correct.
Nositelinkssearchbox
This worth tells Google to not generate a search field to your web site in search outcomes.
For those who don’t use this worth, Google can present a search field to your web site within the SERPs.
Like this:
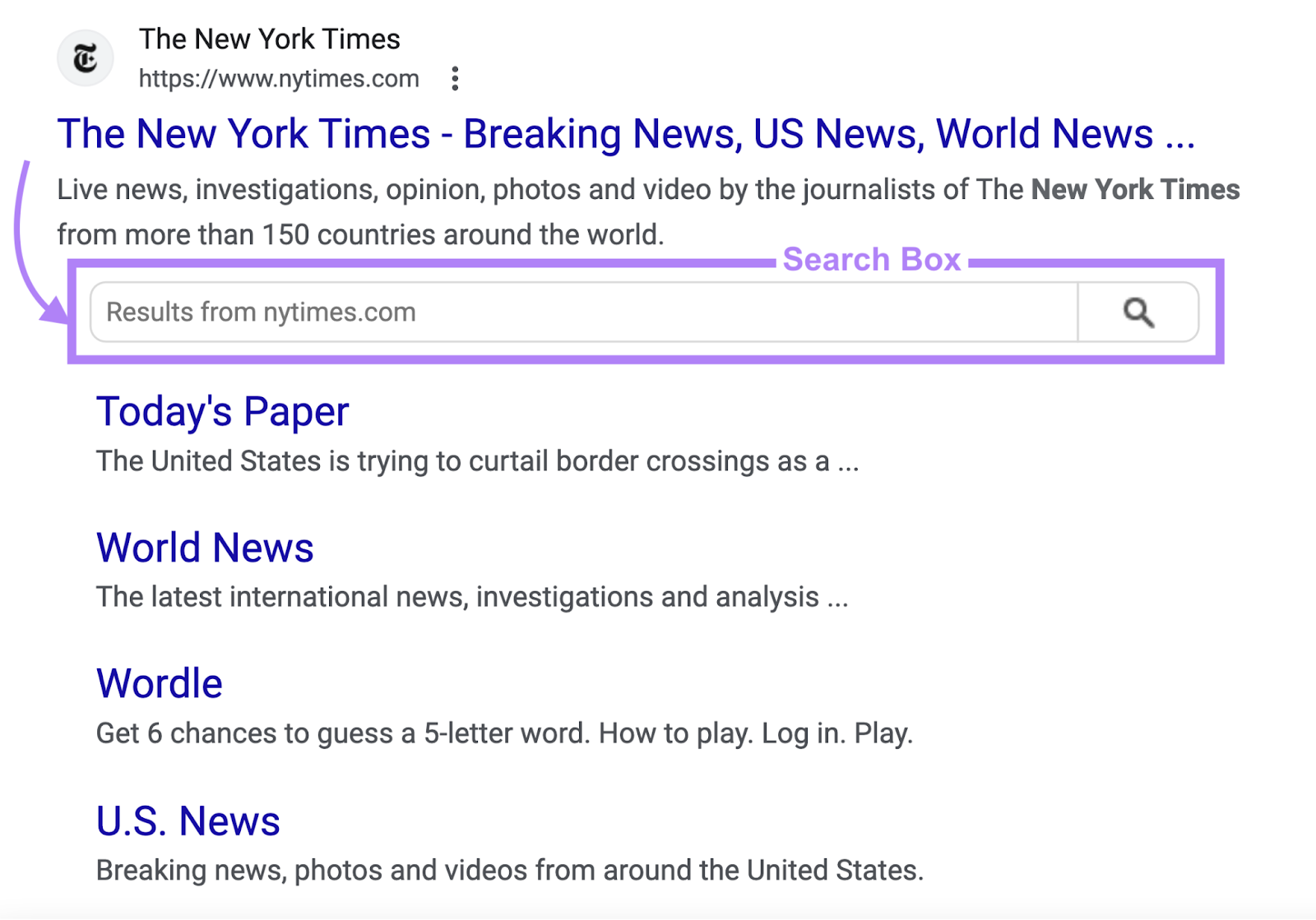
Use this worth when you don’t need the search field to look.
Nosnippet
“Nosnippet” stops Google from exhibiting a textual content snippet or video preview of the web page in search outcomes.
With out this worth, Google can produce snippets of textual content or video primarily based on the web page’s content material.
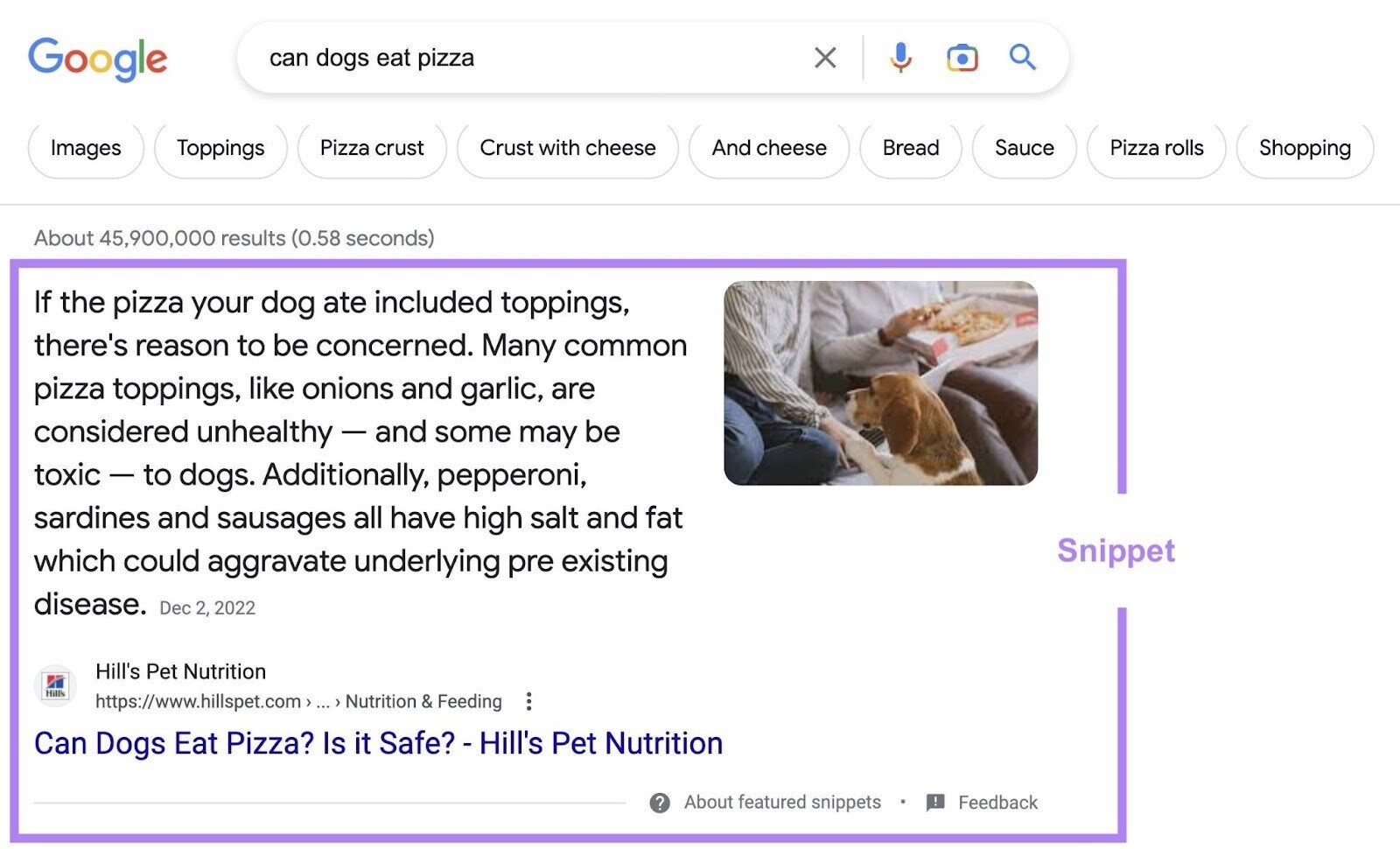
The worth “nosnippet” additionally prevents Google from utilizing your content material as a “direct enter” for AI Overviews. However it’ll additionally forestall meta descriptions, rich snippets, and video previews. So use it with warning.
Whereas not a meta robots tag, you should utilize the “data-nosnippet” attribute to forestall particular sections of your pages from exhibiting in search outcomes.
Like this:
This textual content might be proven in a snippet
however this half would not be proven.
Max-snippet
“Max-snippet” tells Google the utmost character size it may well present as a textual content snippet for the web page in search outcomes.
This attribute has two necessary circumstances to pay attention to:
- 0: Opts your web page out of textual content snippets (as with “nosnippet”)
- -1: Signifies there’s no restrict
For instance, to forestall Google from displaying a textual content snippet within the SERPs, you would use:
Or, if you wish to permit as much as 100 characters:
To point there’s no character restrict:
Max-image-preview
This tells Google the utmost dimension of a preview picture for the web page within the SERPs.
There are three values for this directive:
- None: Google gained’t present a preview picture
- Normal: Google could present a default preview
- Massive: Google could present a bigger preview picture
Max-video-preview
This worth tells Google the utmost size you need it to make use of for a video snippet within the SERPs (in seconds).
As with “max-snippet,” there are two necessary values for this directive:
- 0: Opts your web page out of video snippets
- -1: Signifies there’s no restrict
For instance, the tag under permits Google to serve a video preview of as much as 10 seconds:
Use this rule if you wish to restrict your snippet to point out sure components of your movies. For those who don’t, Google could present a video snippet of any size.
Indexifembedded
When used together with noindex, this (pretty new) tag lets Google index the web page’s content material if it’s embedded in one other web page via HTML parts comparable to iframes.
(It wouldn’t have an impact with out the noindex tag.)
“Indexifembedded” has been created with media publishers in thoughts:
They usually have media pages that shouldn’t be listed. However they do need the media listed when it’s embedded in one other web page’s content material.
Beforehand, they’d have used “noindex” on the media web page. Which might forestall it from being listed on the embedding pages too. “Indexifembedded” solves this.
Unavailable_after
The “unavailable_after” worth prevents Google from exhibiting a web page within the SERPs after a particular date and time.
You have to specify the date and time utilizing RFC 822, RFC 850, or ISO 8601 codecs. Google ignores this rule when you don’t specify a date/time. By default, there isn’t any expiration date for content material.
You should use this worth for limited-time occasion pages, time-sensitive pages, or pages you not deem necessary. This capabilities like a timed noindex tag, so use it with warning. Or you would find yourself with indexing points later down the road.
Combining Robots Meta Tag Guidelines
There are two methods in which you’ll be able to mix robots meta tag guidelines:
- Writing a number of comma-separated values into the “content material” attribute
- Offering two or extra robots meta parts
A number of Values Contained in the ‘Content material’ Attribute
You may combine and match the “content material” values we’ve simply outlined. Simply make sure that to separate them by comma. As soon as once more, the values should not case-sensitive.
For instance:
This tells engines like google to not index the web page or crawl any of the hyperlinks on the web page.
You may mix noindex and nofollow utilizing the “none” worth:
However some engines like google, like Bing, don’t help this worth.
Two or Extra Robots Meta Parts
Use separate robots meta parts if you wish to instruct totally different crawlers to behave in another way.
For instance:
This mix instructs all crawlers to keep away from crawling hyperlinks on the web page. However it additionally tells Yandex particularly to not index the web page (along with not crawling the hyperlinks).
The desk under exhibits the supported meta robots values for various engines like google:
|
Worth |
|
Bing |
Yandex |
|
noindex |
Y |
Y |
Y |
|
noimageindex |
Y |
N |
N |
|
nofollow |
Y |
N |
Y |
|
noarchive |
Y |
Y |
Y |
|
nocache |
N |
Y |
N |
|
nosnippet |
Y |
Y |
N |
|
nositelinkssearchbox |
Y |
N |
N |
|
notranslate |
Y |
N |
N |
|
max-snippet |
Y |
Y |
N |
|
max-video-preview |
Y |
Y |
N |
|
max-image-preview |
Y |
Y |
N |
|
indexifembedded |
Y |
N |
N |
|
unavailable_after |
Y |
N |
N |
Including Robots Meta Tags to Your HTML Code
For those who can edit your web page’s HTML code, add your robots meta tags into the
part of the web page.
For instance, if you would like engines like google to keep away from indexing the web page and to keep away from crawling hyperlinks, use:
Implementing Robots Meta Tags in WordPress
For those who’re utilizing a WordPress plugin like Yoast search engine marketing, open the “Superior” tab within the block under the web page editor.
Set the “noindex” directive by switching the “Enable engines like google to point out this web page in search outcomes?” drop-down to “No.”
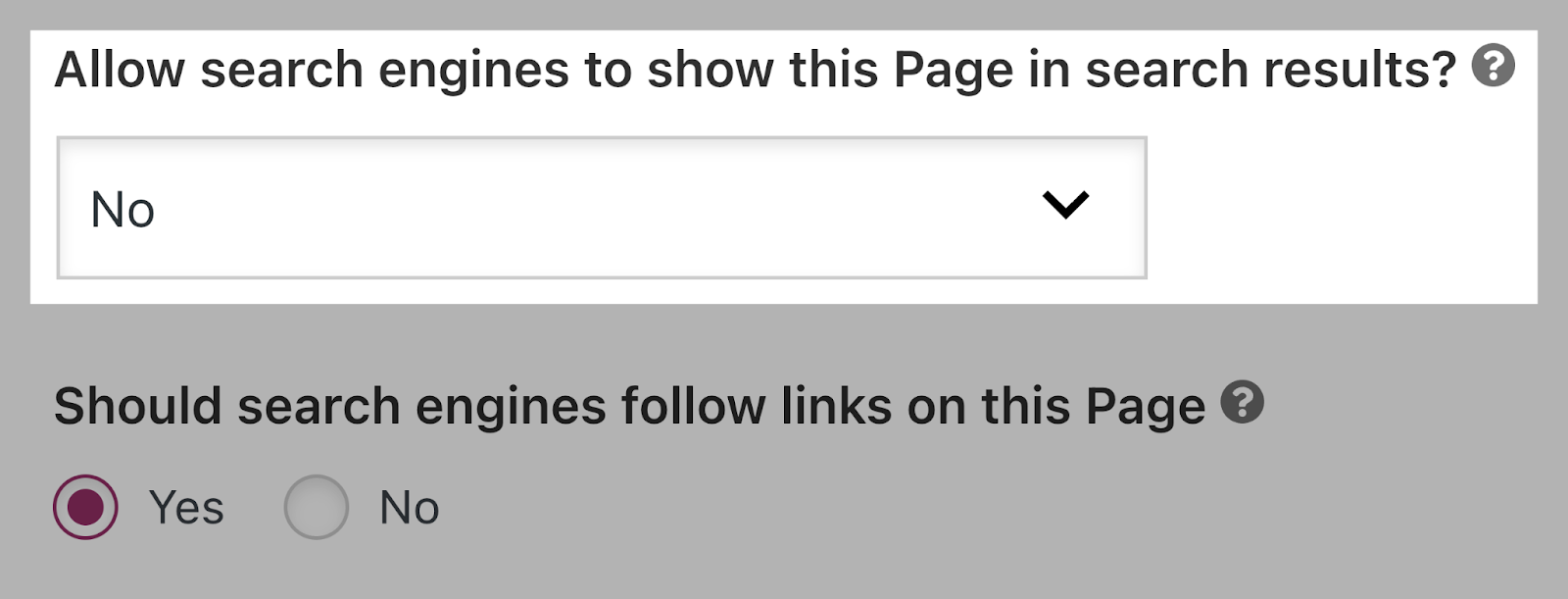
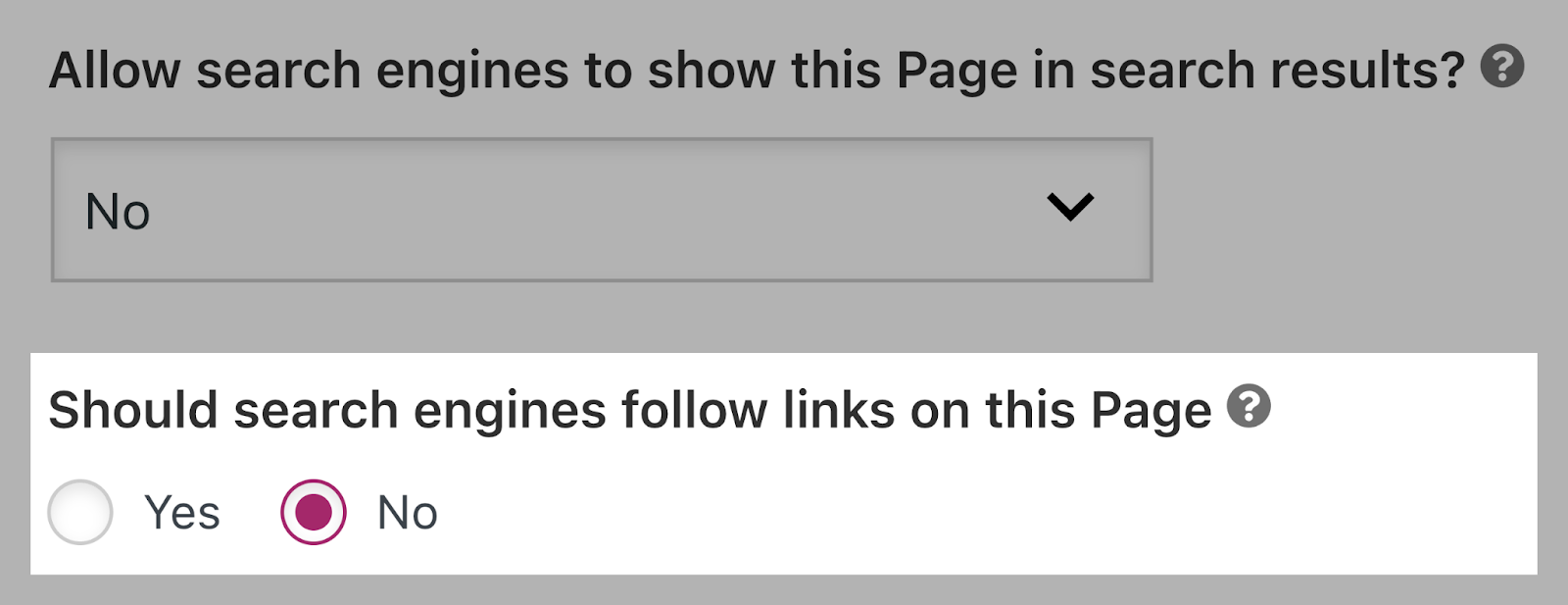
Or forestall engines like google from following hyperlinks by switching the “Ought to engines like google observe hyperlinks on this web page?” to “No.”
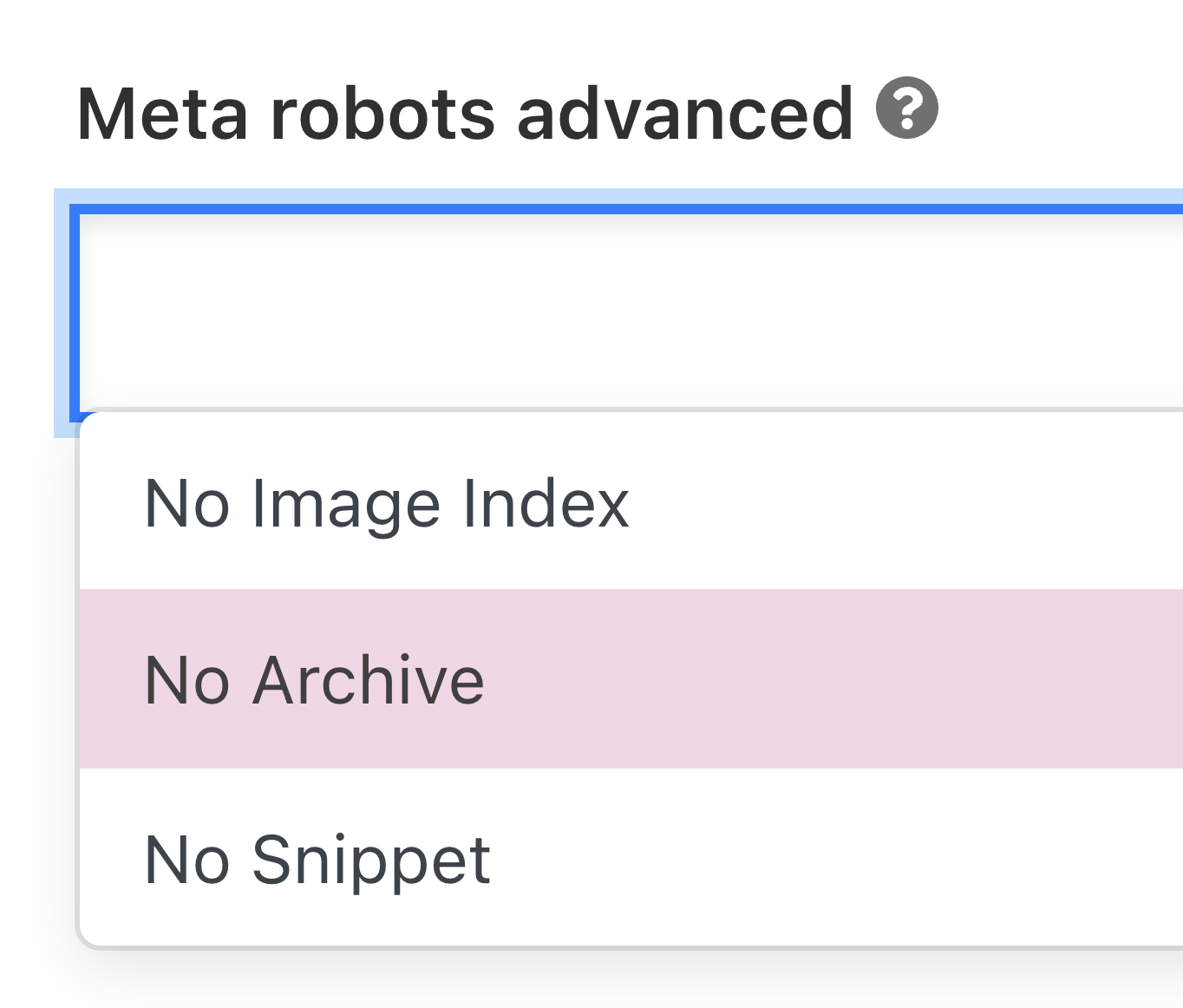
For different directives, it’s important to implement them within the “Meta robots superior” subject.
Like this:
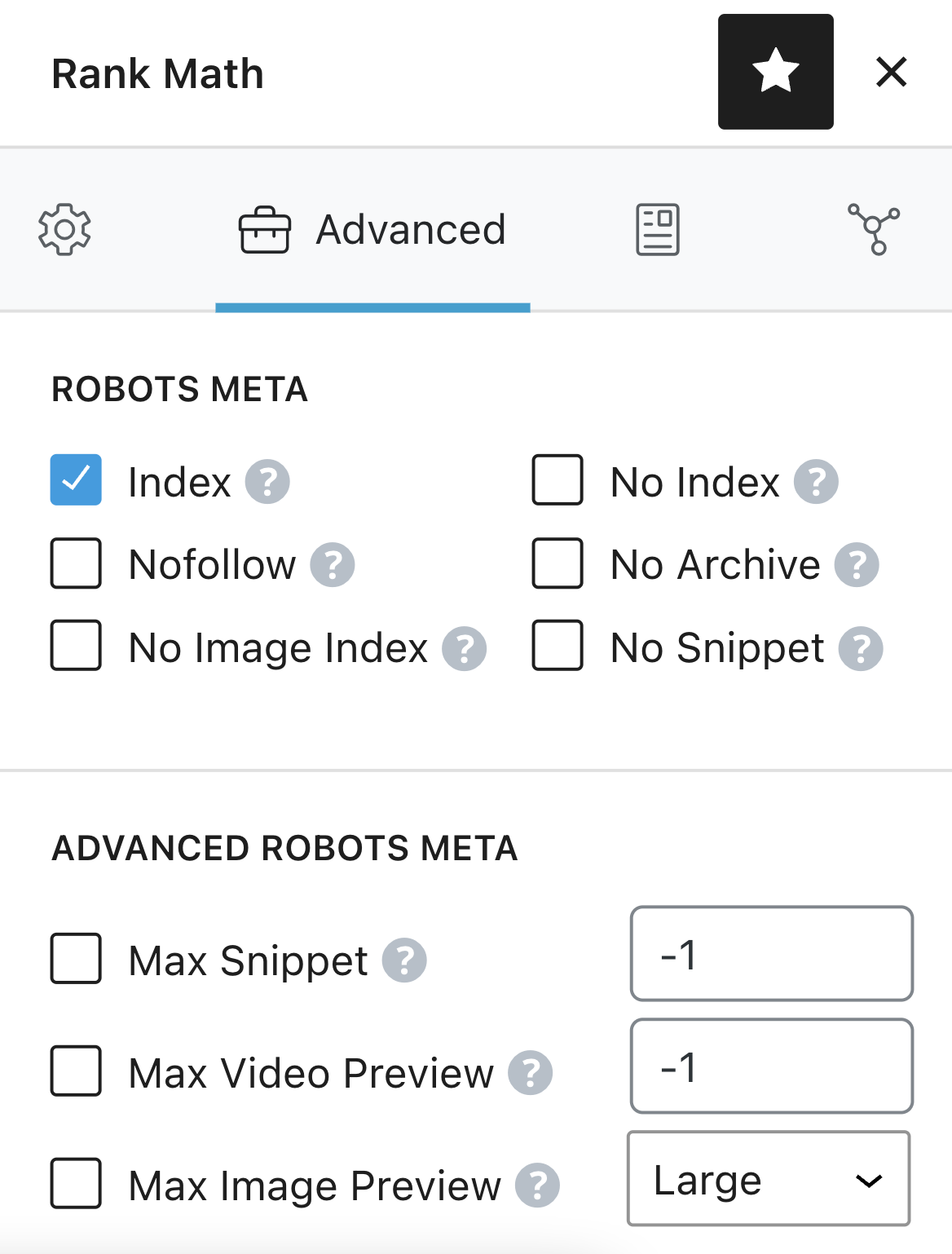
For those who’re utilizing Rank Math, choose the robots directives straight from the “Superior” tab of the meta field.
Like so:
Including Robots Meta Tags in Shopify
To implement robots meta tags in Shopify, edit the
part of your theme.liquid format file.
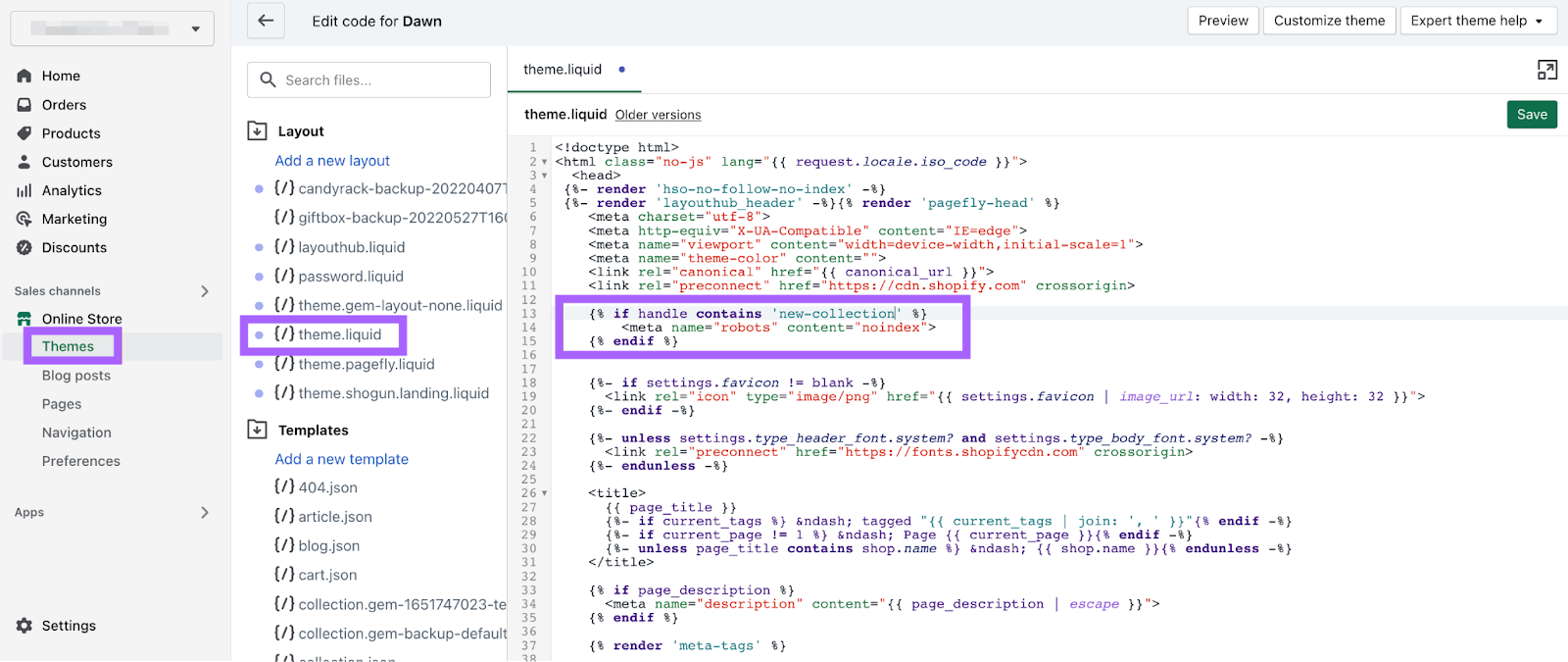
To set the directives for a particular web page, add the code under to the file:
{% if deal with comprises 'page-name' %}
{% endif %}
This instance instructs engines like google to not index /page-name/ (however to nonetheless observe all of the hyperlinks on the web page).
You have to create separate entries to set the directives throughout totally different pages.
Implementing Robots Meta Tags in Wix
Open your Wix dashboard and click on “Edit Website.”
Click on “Pages & Menu” within the left-hand navigation.
Within the tab that opens, click on “…” subsequent to the web page you wish to set robots meta tags for. Select “search engine marketing fundamentals.”
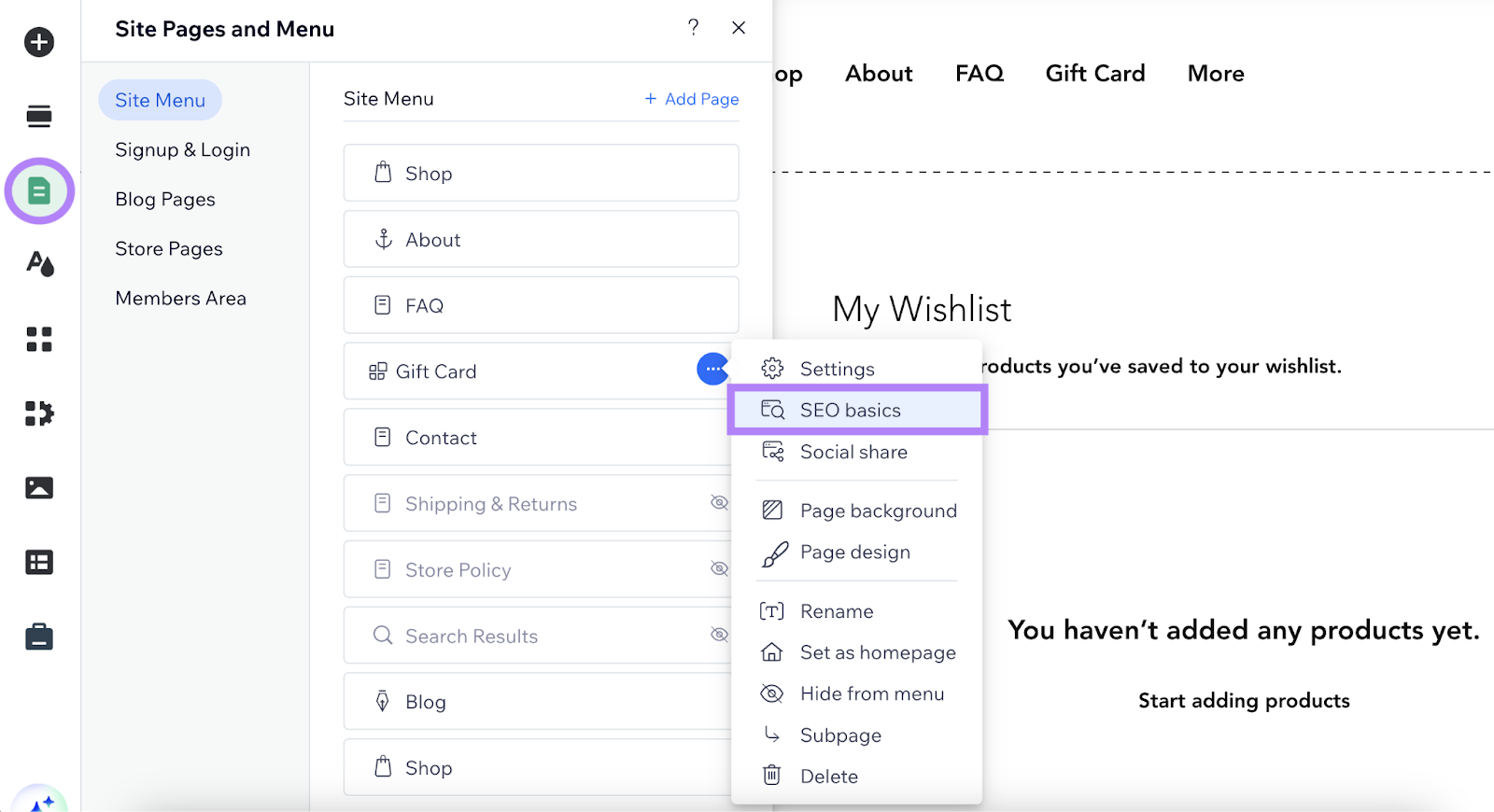
Then click on “Superior search engine marketing” and click on on the collapsed merchandise “Robots meta tag.”
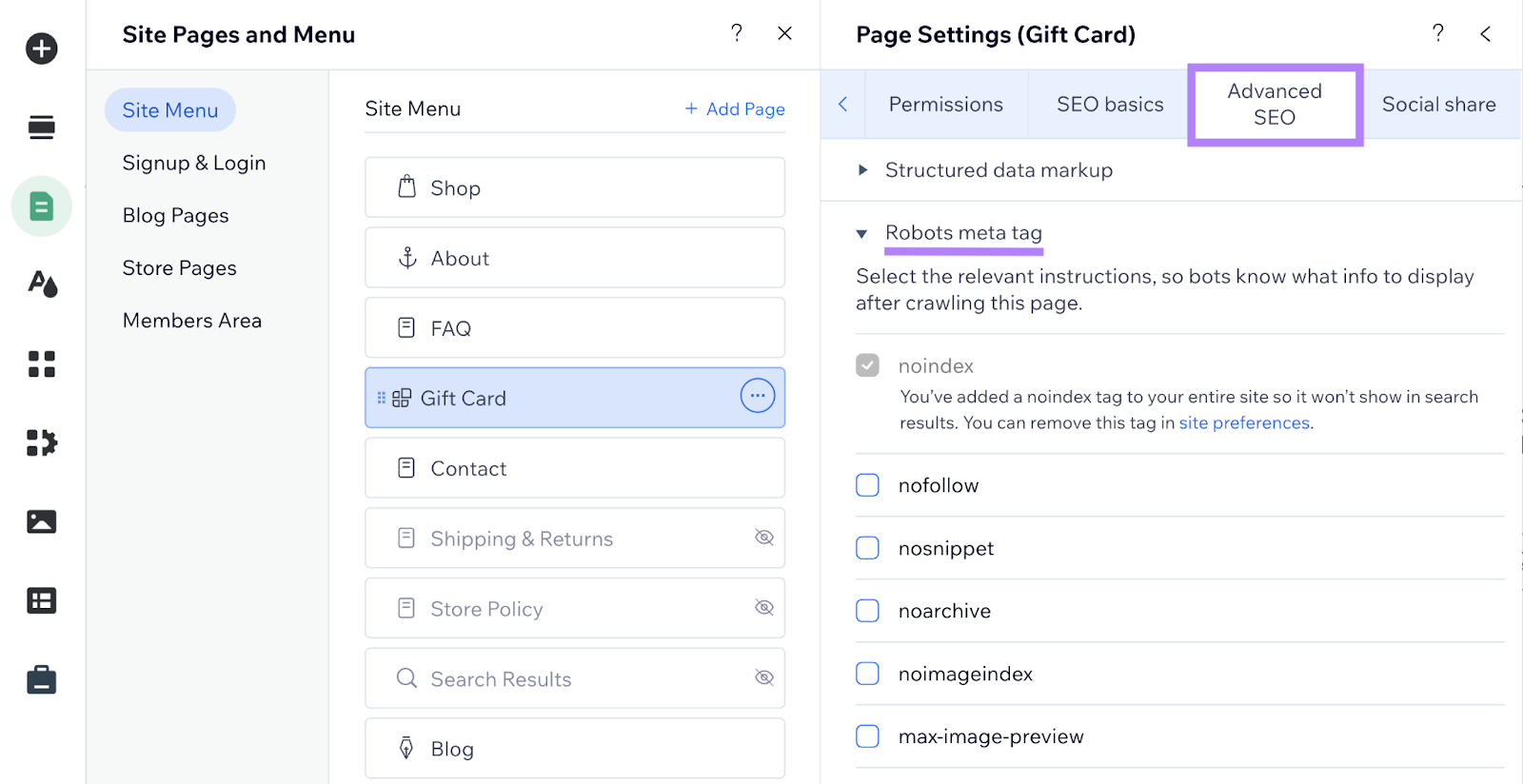
Now you possibly can set the related robots meta tags to your web page by clicking the checkboxes.
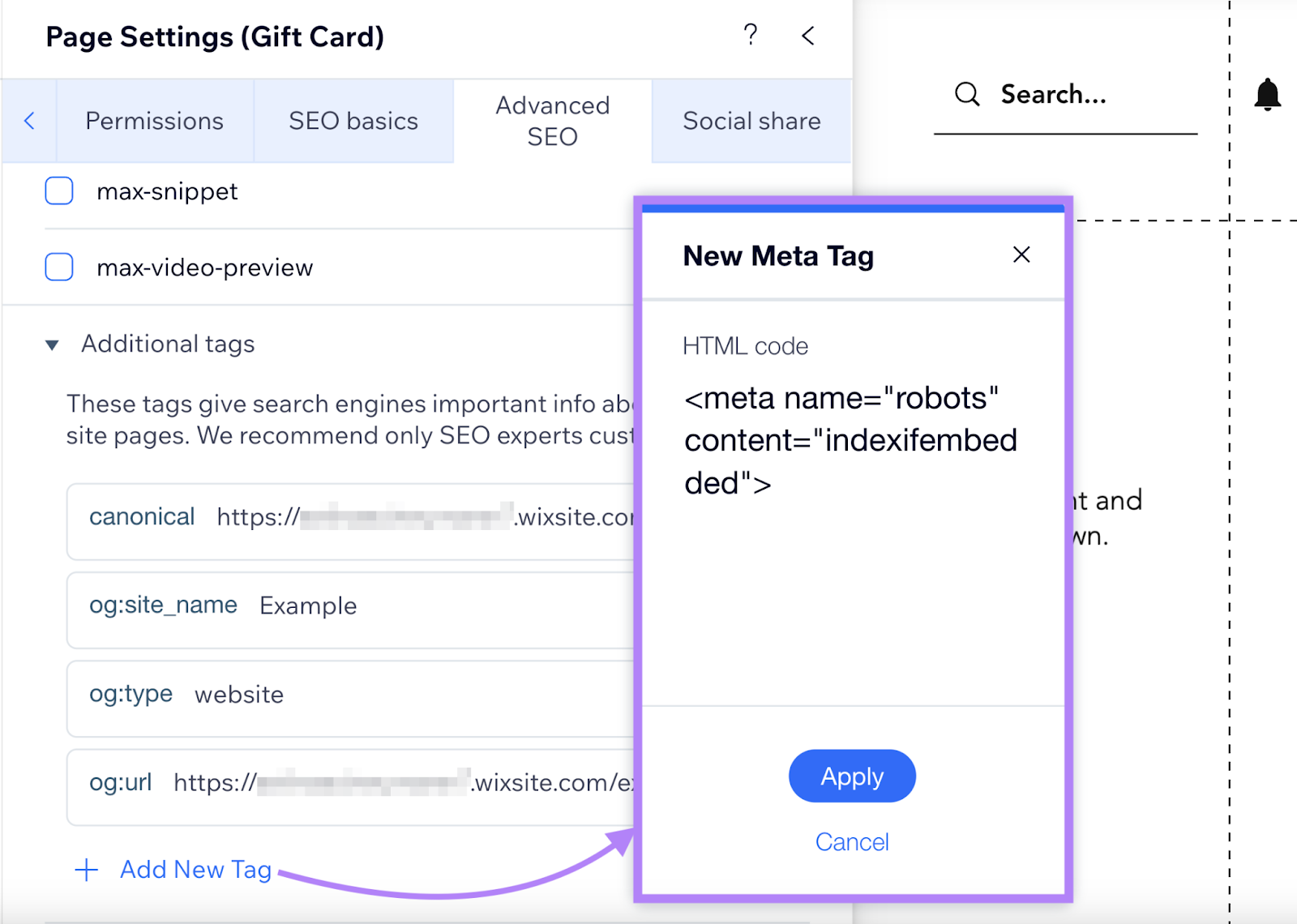
For those who want “notranslate,” “nositelinkssearchbox,” “indexifembedded,” or “unavailable_after,” click on “Extra tags”and “Add New Tags.”
Now you possibly can paste your meta tag in HTML format.
What Is the X-Robots-Tag?
An x-robots-tag serves the identical operate as a meta robots tag however for non-HTML recordsdata. Equivalent to photos and PDFs.
You embrace it as a part of the HTTP header response for a URL.
Like this:

To implement the x-robots-tag, you may have to entry your web site’s header.php, .htaccess, or server configuration file. You should use the identical guidelines as these we mentioned earlier for meta robots tags.
Utilizing X-Robots-Tag on an Apache Server
To make use of the x-robots-tag on an Apache net server, add the next to your web site’s .htaccess file or httpd.conf file.
Header set X-Robots-Tag "noindex, nofollow"
For instance, the code above instructs engines like google to not index or to observe any hyperlinks on all PDFs throughout your entire web site.
Utilizing X-Robots-Tag on an Nginx Server
For those who’re working an Nginx server, add the code under to your web site’s .conf file:
location ~* .pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
The instance code above will apply noindex and nofollow values to all the web site’s PDFs.
Let’s check out some widespread errors to keep away from when utilizing meta robots and x-robots-tags:
Utilizing Meta Robots Directives on a Web page Blocked by Robots.txt
For those who disallow crawling of a web page in your robots.txt file, main search engine bots gained’t crawl it. So any meta robots tags or x-robots-tags on that web page can be ignored.
Guarantee engines like google can crawl any pages with meta robots tags or x-robots-tags.
Including Robots Directives to the Robots.txt File
Though by no means formally supported by Google, you had been as soon as in a position so as to add a “noindex” directive to your web site’s robots.txt file.
That is not an possibility, as confirmed by Google.
The “noindex” rule in robots meta tags is the simplest technique to take away URLs from the index while you do permit crawling.
Eradicating Pages with a Noindex Directive from Sitemaps
For those who’re making an attempt to take away a web page from the index utilizing a “noindex” directive, go away the web page in your sitemap till it has been eliminated.
Eradicating the web page earlier than it’s deindexed could cause delays in deindexing.
Not Eradicating the ‘Noindex’ Directive from a Staging Surroundings
Stopping robots from crawling pages in your staging web site is a greatest apply. However it’s straightforward to neglect to take away “noindex” as soon as the location strikes into manufacturing.
And the outcomes may be disastrous. As engines like google could by no means crawl and index your web site.
To keep away from these points, examine that your robots meta tags are right earlier than transferring your web site from a staging platform to a stay surroundings.
Discovering and fixing crawlability issues (and different technical search engine marketing errors) in your web site can dramatically enhance efficiency.
For those who don’t know the place to start out, use Semrush’s Site Audit device.
Simply enter your area and click on “Begin Audit.”
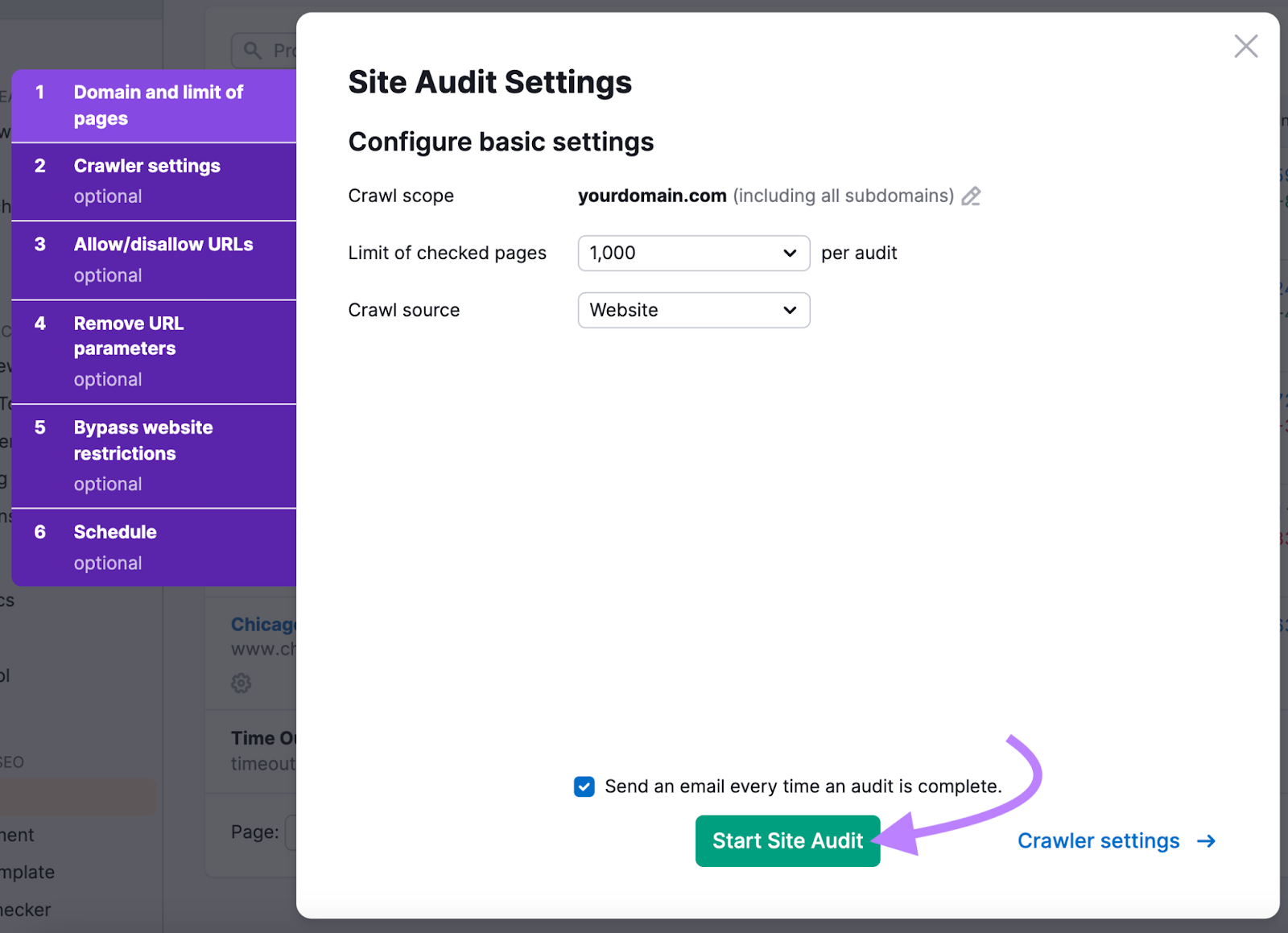
You may configure numerous settings, just like the variety of pages to crawl and which crawler you’d like to make use of. However it’s also possible to simply go away them as their defaults.
If you’re prepared, click on “Begin Website Audit.”
When the audit is full, head to the “Points” tab.
Within the search field, sort “blocked from crawling” to see errors concerning your meta robots tags or x-robots-tags.
Like this:
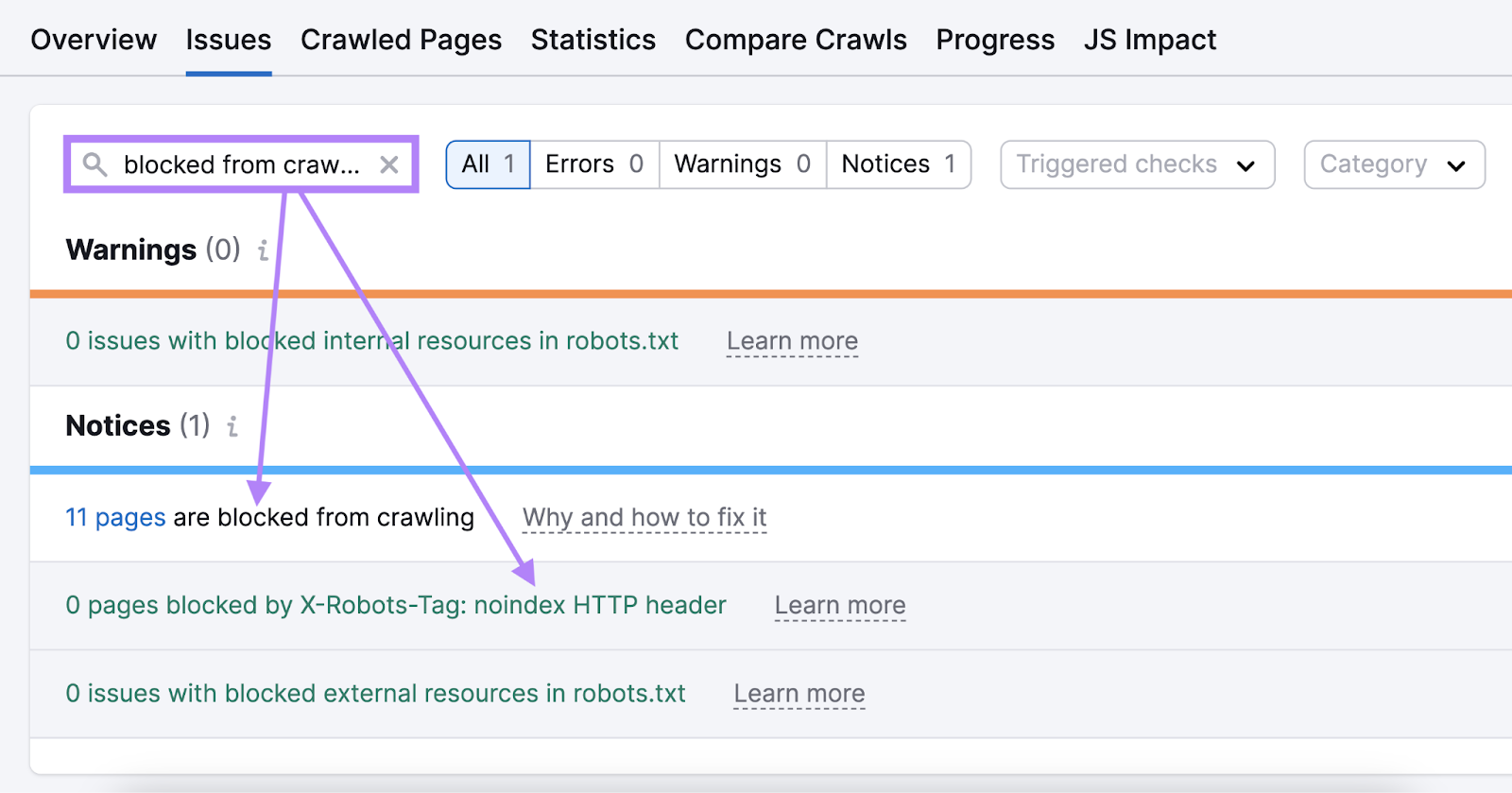
Click on on “Why and the best way to repair it” subsequent to a difficulty to learn extra in regards to the situation and the best way to repair it.
Repair every of those points to enhance your web site’s crawlability. And to make it simpler for Google to search out and index your content material.
FAQs
When Ought to You Use the Robots Meta Tag vs. X-Robots-Tag?
Use the robots meta tag for HTML pages and the x-robots-tag for different non-HTML assets. Like PDFs and pictures.
This isn’t a technical requirement. You could possibly inform crawlers what to do together with your webpages by way of x-robots-tags. However it’s simpler to attain the identical factor by implementing the robots meta tags on a webpage.
You can even use x-robots-tags to use directives in bulk. Slightly than merely on a web page degree.
Do You Must Use Each Meta Robots Tag and X-Robots-Tag?
You don’t want to make use of each meta robots tags and x-robots-tags. Telling crawlers the best way to index your web page utilizing both a meta robots or x-robots-tag is sufficient.
Repeating the instruction gained’t improve the possibilities that Googlebot or some other crawlers will observe it.
What Is the Best Approach to Implement Robots Meta Tags?
Utilizing a plugin is often the simplest manner so as to add robots meta tags to your webpages. As a result of it doesn’t often require you to edit any of your web site’s code.
Which plugin it’s best to use is dependent upon the content material administration system (CMS) you’re utilizing.
Robots meta tags make it possible for the content material you’re placing a lot effort into will get listed. If engines like google don’t index your content material, you possibly can’t generate any natural visitors.
So, getting the fundamental robots meta tag parameters proper (like noindex and nofollow) is totally essential.
Examine that you simply’re implementing these tags appropriately utilizing Semrush Site Audit.
This submit was up to date in 2024. Excerpts from the unique article by Carlos Silva could stay.


