

What Is Crawl Finances?
Crawl funds is the variety of URLs in your web site that serps like Google will crawl (uncover) in a given time interval. And after that, they’ll transfer on.
Right here’s the factor:
There are billions of internet sites on the planet. And serps have restricted assets—they will’t verify each single web site day by day. So, they should prioritize what and when to crawl.
Earlier than we speak about how they try this, we have to focus on why this issues on your web site’s website positioning.
Why Is Crawl Finances Essential for website positioning?
Google first must crawl after which index your pages earlier than they will rank. And all the things must go easily with these processes on your content material to indicate in search outcomes.
That may considerably affect your organic traffic. And your total enterprise targets.
Most web site house owners don’t want to fret an excessive amount of about crawl funds. As a result of Google is sort of environment friendly at crawling web sites.
However there are just a few particular conditions when Google’s crawl funds is particularly essential for website positioning:
- Your web site could be very giant: In case your web site is giant and complicated (10K+ pages), Google won’t discover new pages immediately or recrawl all your pages fairly often
- You add plenty of new pages: If you happen to ceaselessly add plenty of new pages, your crawl funds can affect the visibility of these pages
- Your web site has technical points: If crawlability issues stop serps from effectively crawling your web site, your content material could not present up in search outcomes
How Does Google Decide Crawl Finances?
Your crawl funds is set by two foremost components:
Crawl Demand
Crawl demand is how typically Google crawls your web site based mostly on perceived significance. And there are three elements that have an effect on your web site’s crawl demand:
Perceived Stock
Google will normally attempt to crawl all or a lot of the pages that it is aware of about in your web site. Until you instruct Google to not.
This implies Googlebot should still attempt to crawl duplicate pages and pages you’ve eliminated in the event you don’t inform it to skip them. Resembling by means of your robots.txt file (extra on that later) or 404/410 HTTP status codes.
Recognition
Google usually prioritizes pages with extra backlinks (hyperlinks from different web sites) and people who entice larger visitors on the subject of crawling. Which may each sign to Google’s algorithm that your web site is essential and value crawling extra ceaselessly.
Notice the variety of backlinks alone doesn’t matter—backlinks must be related and from authoritative sources.
Use Semrush’s Backlink Analytics device to see which of your pages entice essentially the most backlinks and will entice Google’s consideration.
Simply enter your area and click on “Analyze.”

You’ll see an outline of your web site’s backlink profile. However to see backlinks by web page, click on the “Listed Pages” tab.
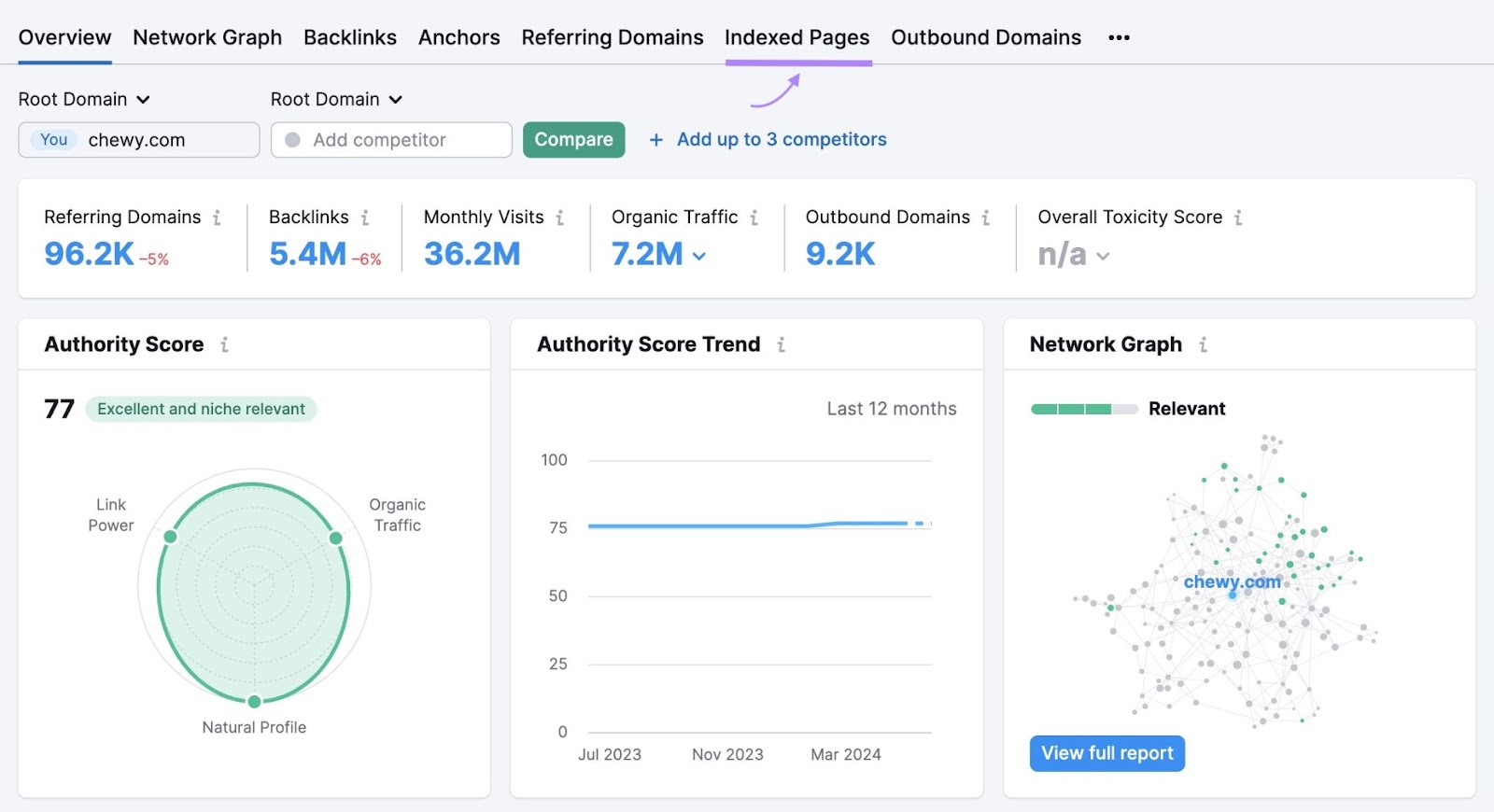
Click on the “Backlinks” column to type by the pages with essentially the most backlinks.
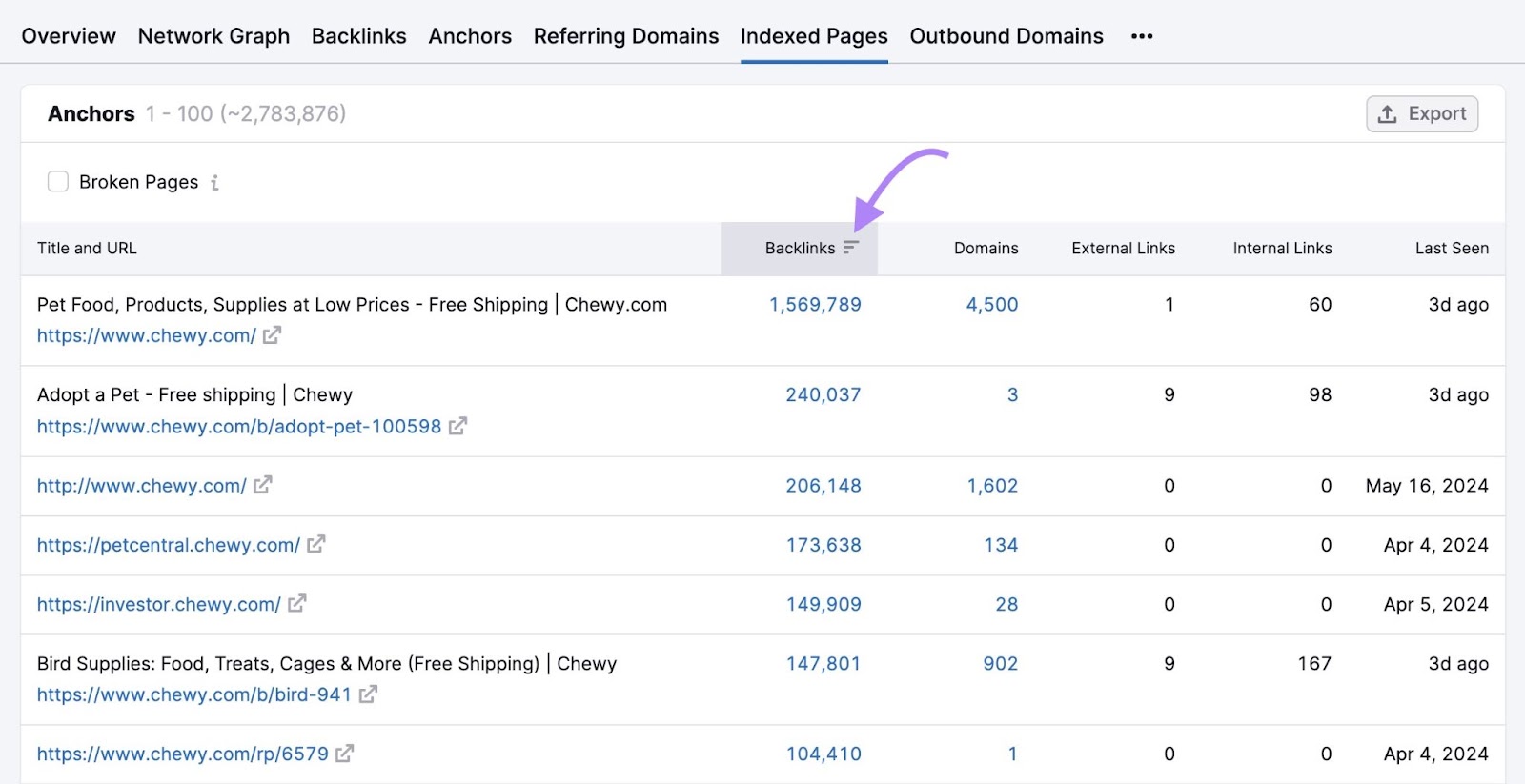
These are seemingly the pages in your web site that Google crawls most ceaselessly (though that’s not assured).
So, look out for essential pages with few backlinks—they might be crawled much less typically. And contemplate implementing a backlinking strategy to get extra websites to hyperlink to your essential pages.
Staleness
Engines like google intention to crawl content material ceaselessly sufficient to choose up any modifications. But when your content material doesn’t change a lot over time, Google could begin crawling it much less ceaselessly.
For instance, Google sometimes crawls information web sites quite a bit as a result of they typically publish new content material a number of instances a day. On this case, the web site has excessive crawl demand.
This doesn’t imply you could replace your content material day by day simply to attempt to get Google to crawl your web site extra typically. Google’s own guidance says it solely needs to crawl high-quality content material.
So prioritize content material high quality over making frequent, irrelevant modifications in an try to spice up crawl frequency.
Crawl Capability Restrict
The crawl capability restrict prevents Google’s bots from slowing down your web site with too many requests, which might trigger efficiency points.
It’s primarily affected by your web site’s total well being and Google’s personal crawling limits.
Your Web site’s Crawl Well being
How briskly your web site responds to Google’s requests can have an effect on your crawl funds.
In case your web site responds rapidly, your crawl capability restrict can enhance. And Google could crawl your pages quicker.
But when your web site slows down, your crawl capability restrict could lower.
In case your web site responds with server errors, this could additionally cut back the restrict. And Google could crawl your web site much less typically.
Google’s Crawling Limits
Google doesn’t have limitless assets to spend crawling web sites. That’s why there are crawl budgets within the first place.
Mainly, it’s a approach for Google to prioritize which pages to crawl most frequently.
If Google’s assets are restricted for one purpose or one other, this could have an effect on your web site’s crawl capability restrict.
The way to Verify Your Crawl Exercise
Google Search Console (GSC) supplies full details about how Google crawls your web site. Together with any points there could also be and any main modifications in crawling conduct over time.
This can assist you perceive if there could also be points impacting your crawl funds that you may repair.
To search out this info, entry your GSC property and click on “Settings.”
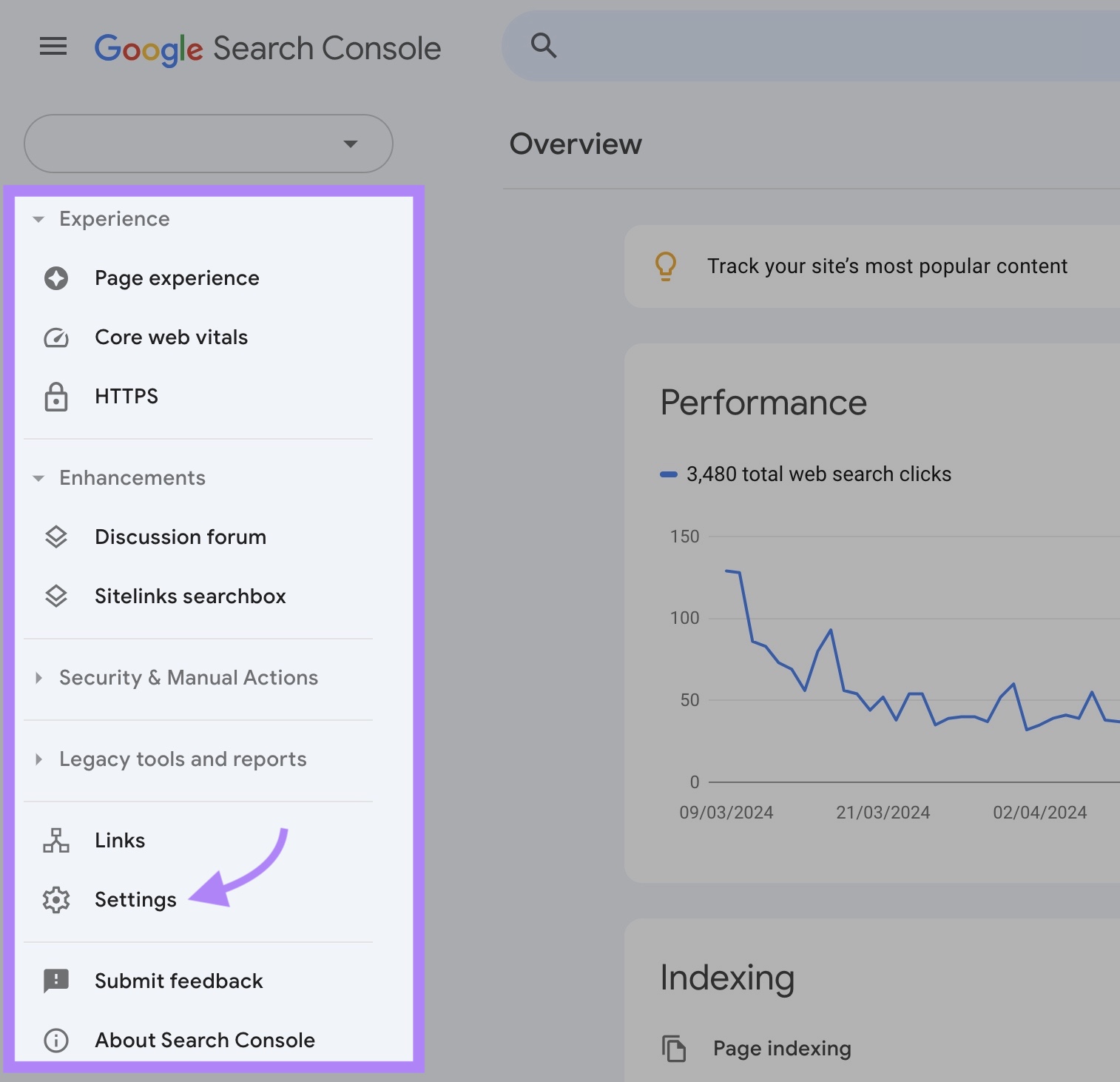
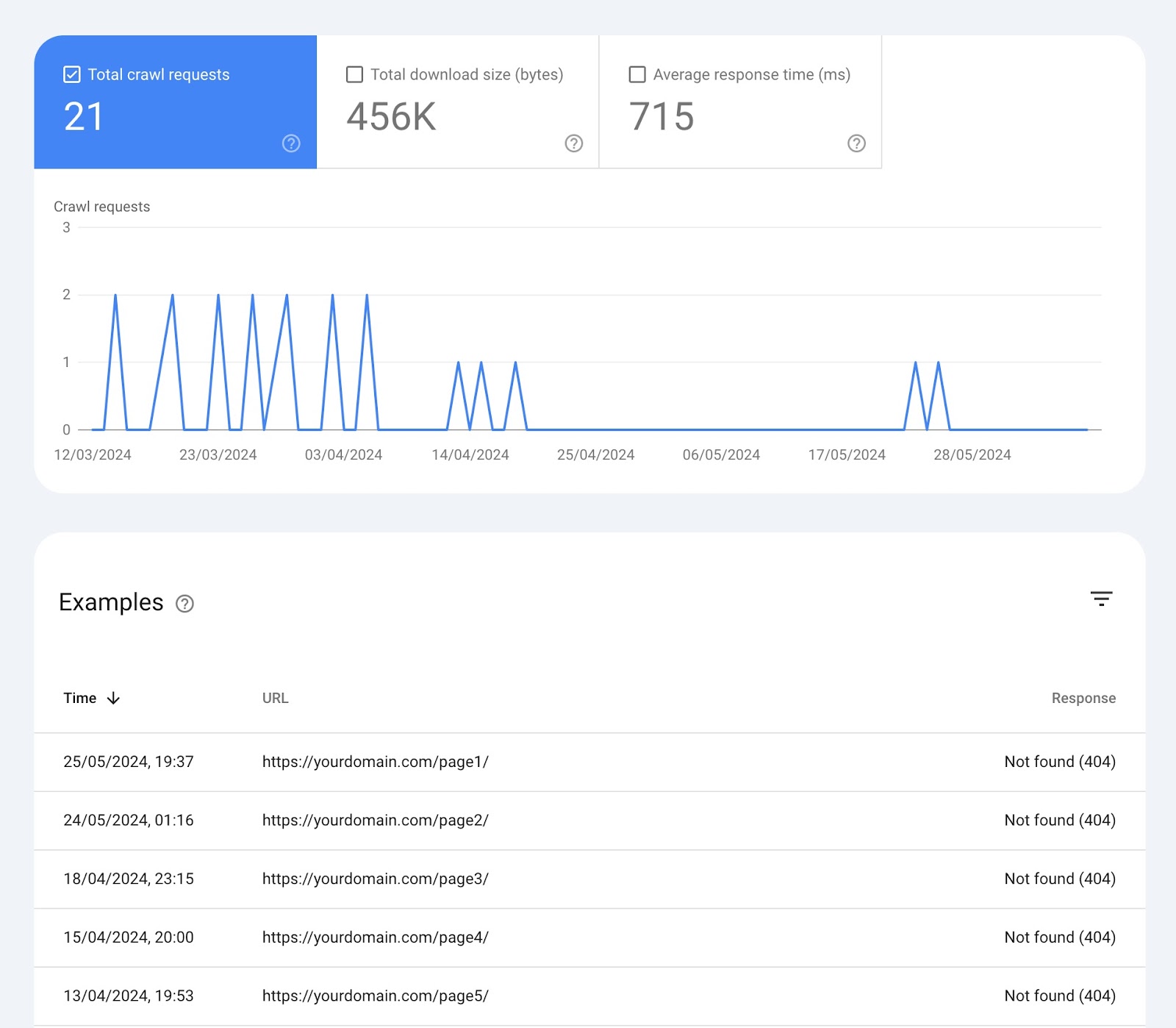
Within the “Crawling” part, you’ll see the variety of crawl requests previously 90 days.
Click on “Open Report” to get extra detailed insights.
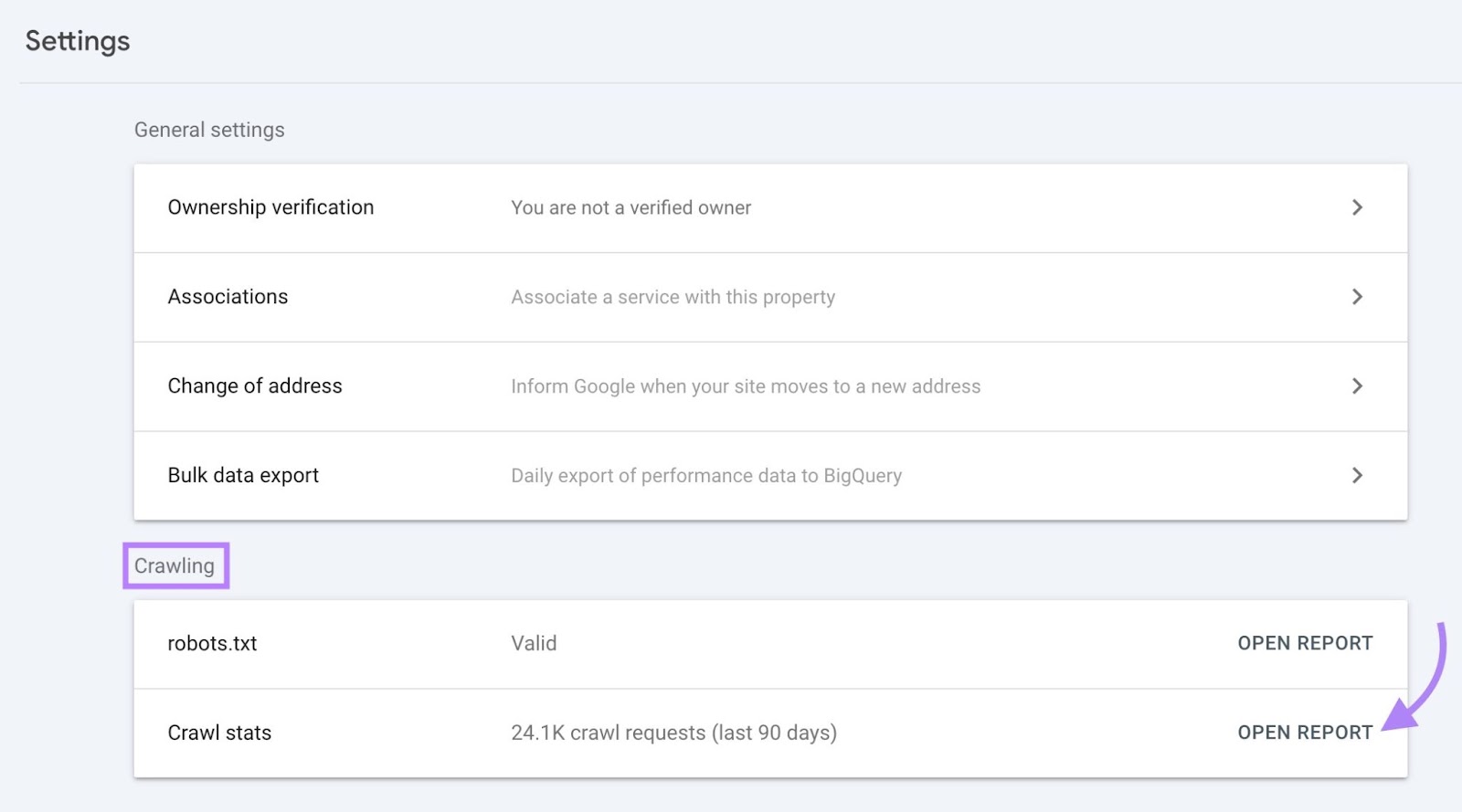
The “Crawl stats” web page exhibits you numerous widgets with information:
Over-Time Charts
On the prime, there’s a chart of crawl requests Google has made to your web site previously 90 days.
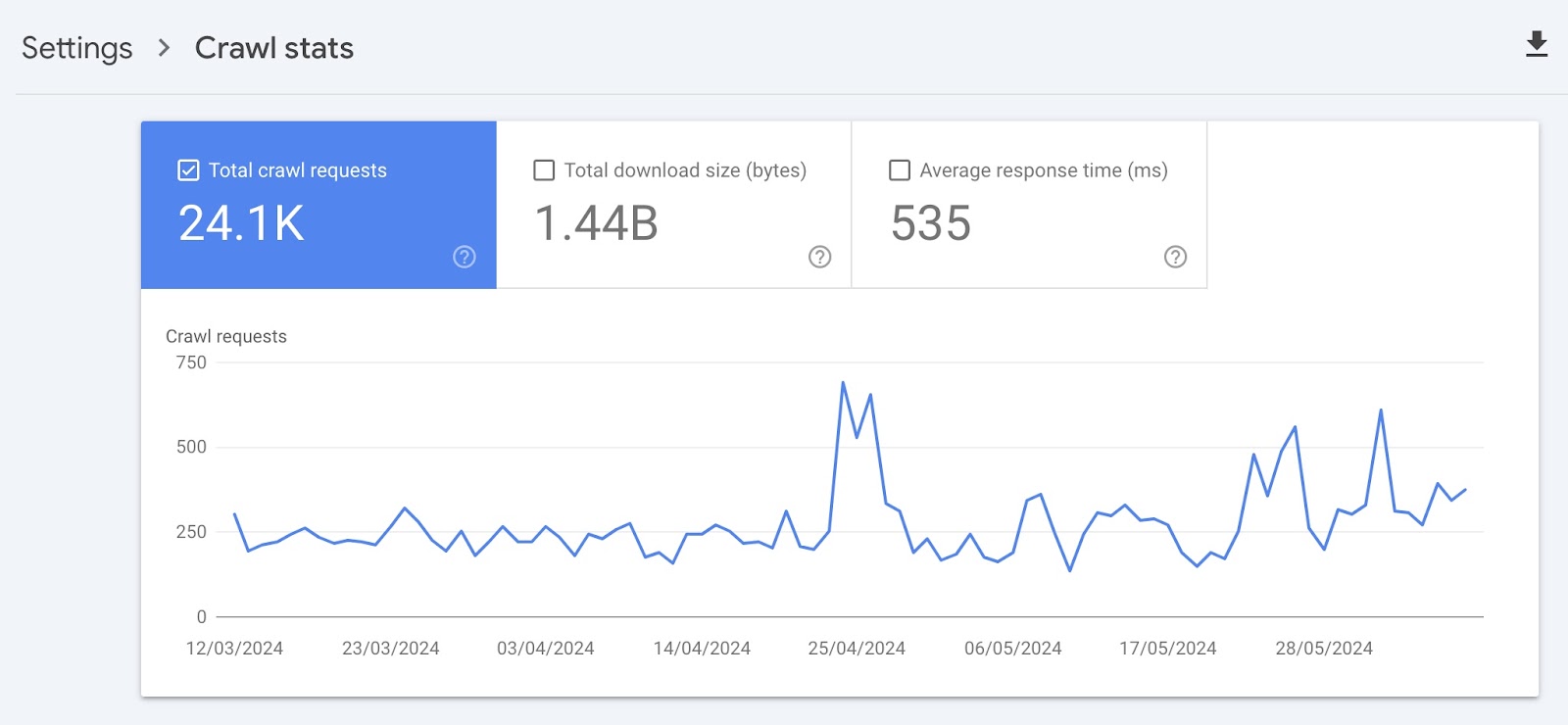
Right here’s what every field on the prime means:
- Complete crawl requests: The variety of crawl requests Google made previously 90 days
- Complete obtain dimension: The whole quantity of knowledge Google’s crawlers downloaded when accessing your web site over a particular interval
- Common response time: The common period of time it took on your web site’s server to answer a request from the crawler (in milliseconds)
Host Standing
Host standing exhibits how simply Google can crawl your web site.
For instance, in case your web site wasn’t all the time in a position to meet Google’s crawl calls for, you would possibly see the message “Host had issues previously.”
If there are any issues, you’ll be able to see extra particulars by clicking this field.
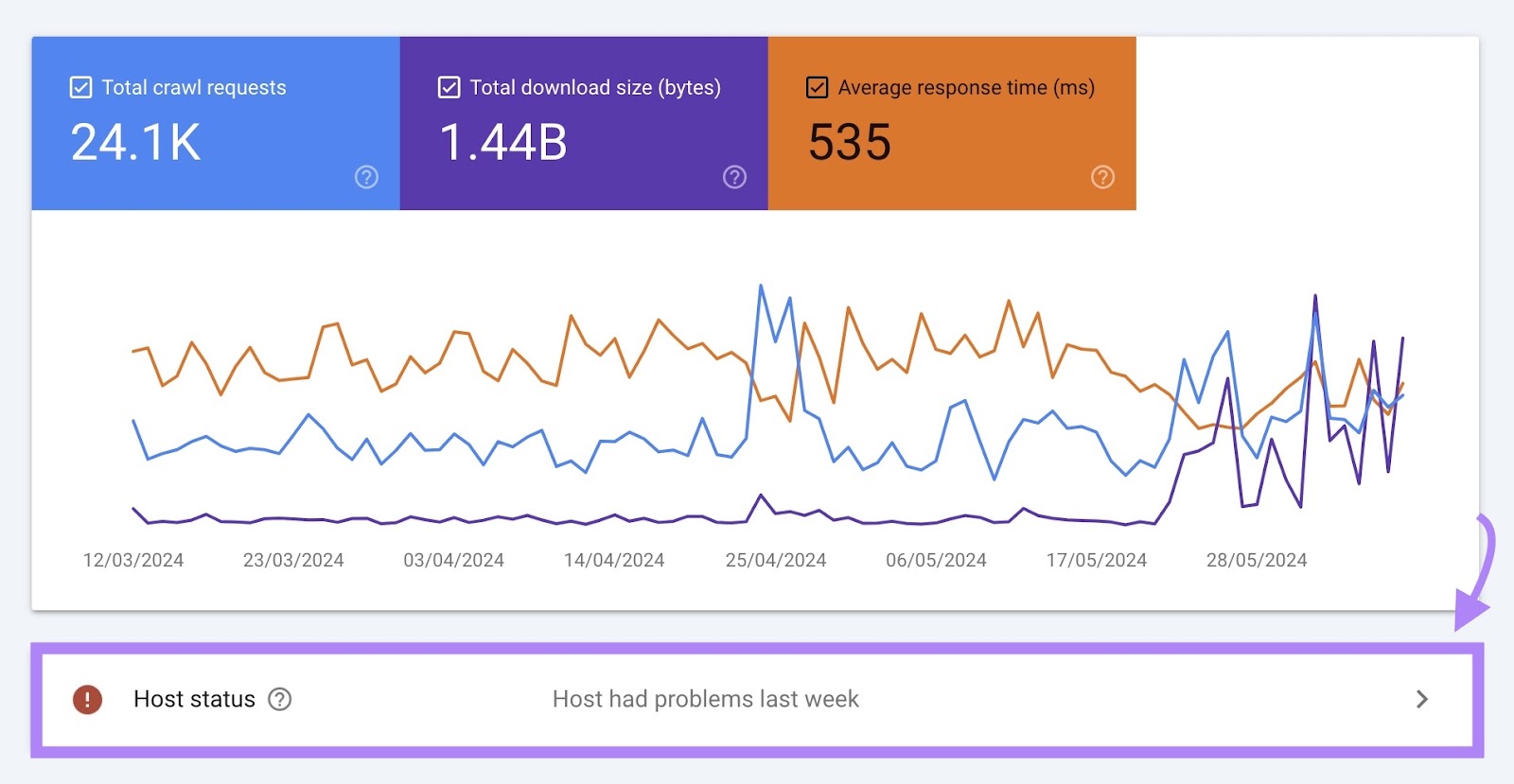
Beneath “Particulars” you’ll discover extra details about why the problems occurred.
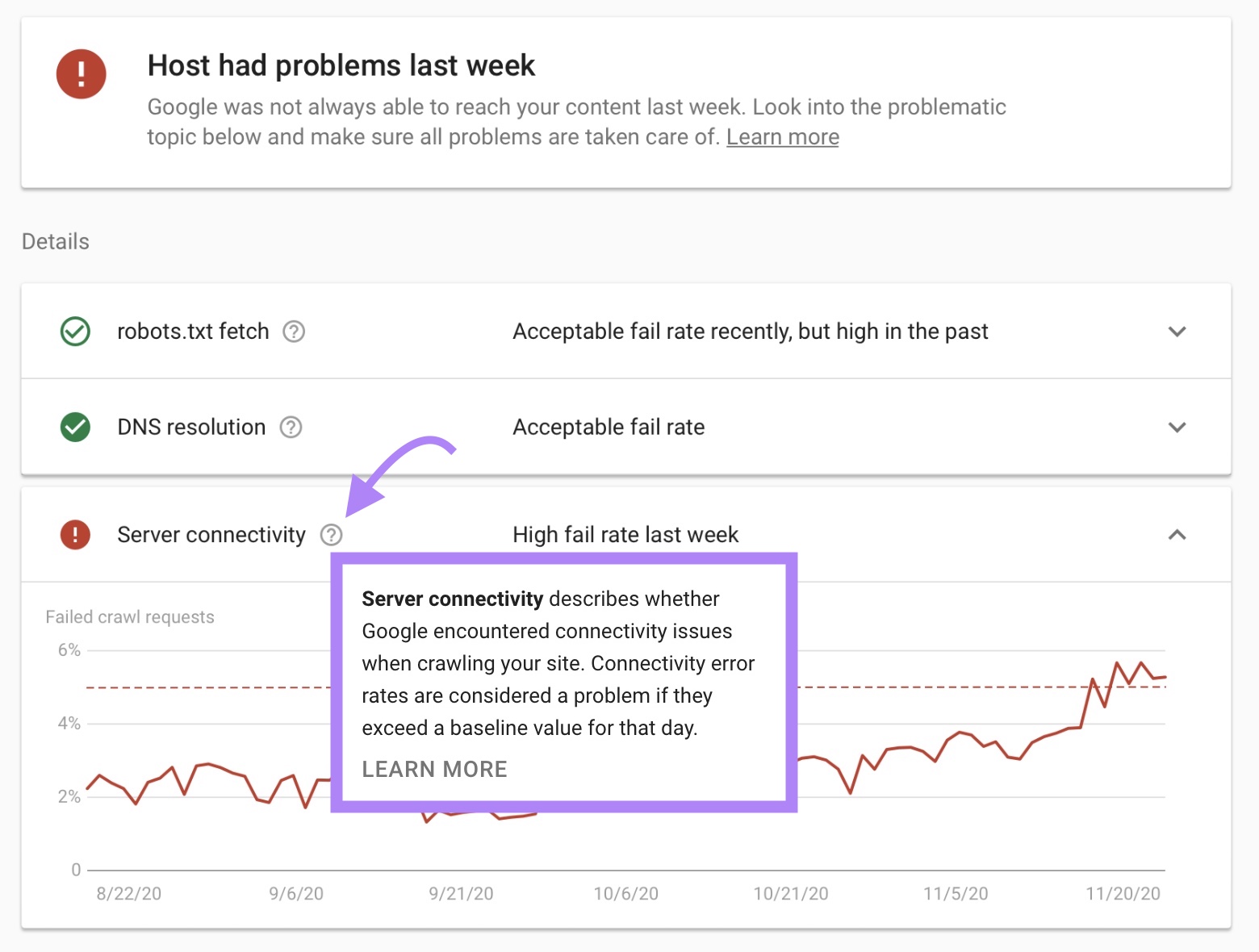
This can present you if there are any points with:
- Fetching your robots.txt file
- Your area title system (DNS)
- Server connectivity
Crawl Requests Breakdown
This part of the report supplies info on crawl requests and teams them in accordance with:
- Response (e.g., “OK (200)” or “Not discovered (404)”
- URL file sort (e.g., HTML or picture)
- Function of the request (“Discovery” for a brand new web page or “Refresh” for an current web page)
- Googlebot sort (e.g., smartphone or desktop)
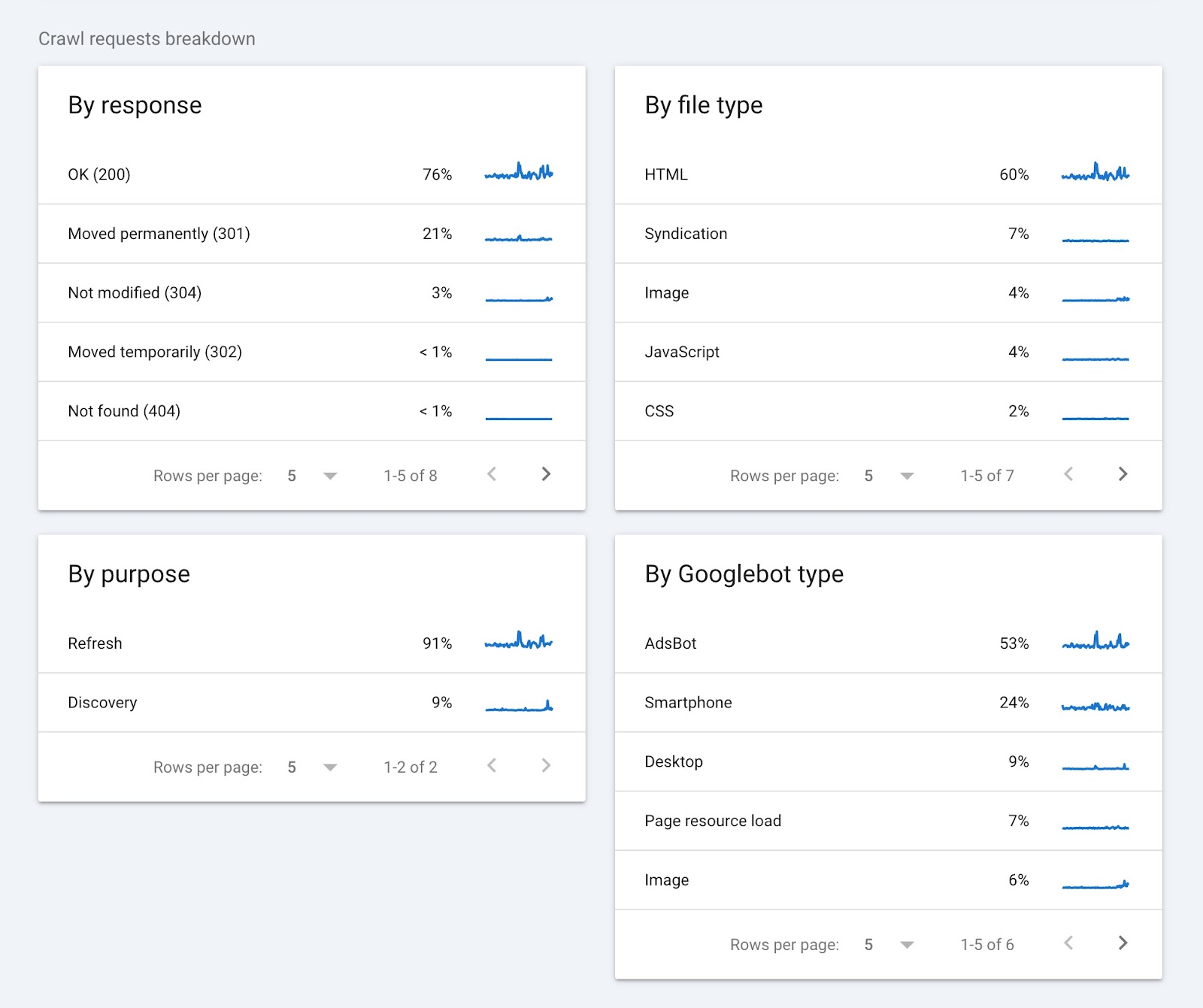
Clicking on any of the gadgets in every widget will present you extra particulars. Such because the pages that returned a particular standing code.
Google Search Console can present helpful details about your crawl funds straight from the supply. However different instruments can present extra detailed insights you could enhance your web site’s crawlability.
The way to Analyze Your Web site’s Crawlability
Semrush’s Site Audit device exhibits you the place your crawl funds is being wasted and can assist you optimize your web site for crawling.
Right here’s the right way to get began:
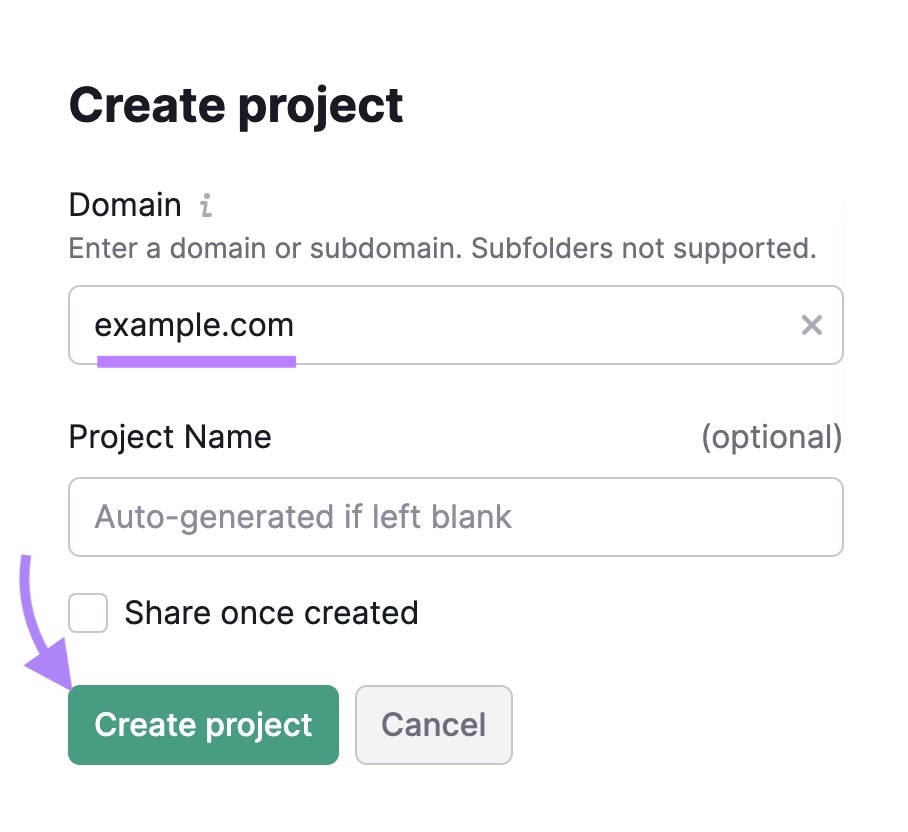
Open the Site Audit device. If that is your first audit, you’ll must create a brand new venture.
Simply enter your area, give the venture a reputation, and click on “Create venture.”
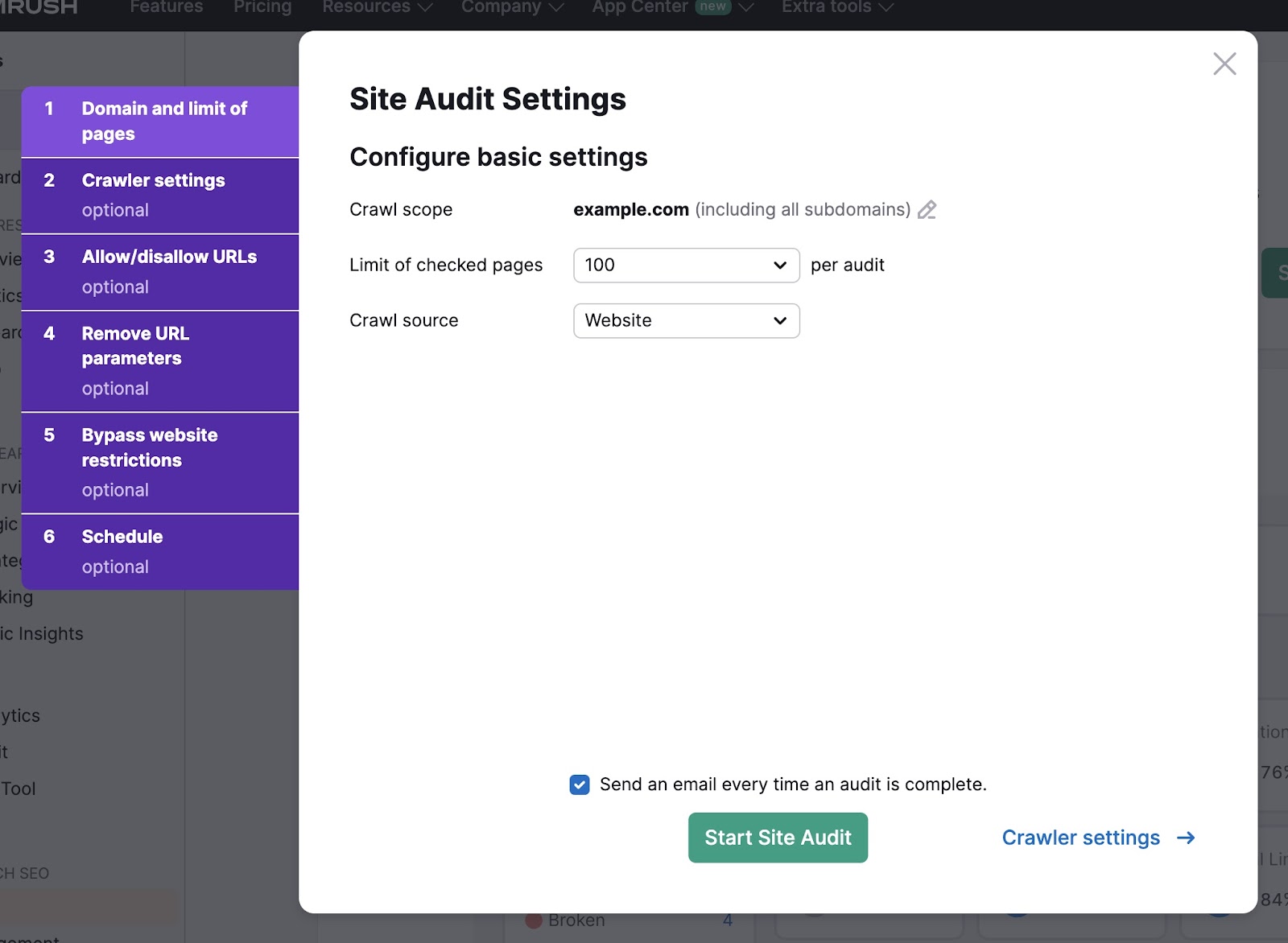
Subsequent, choose the variety of pages to verify and the crawl supply.
In order for you the device to crawl your web site instantly, choose “Web site” because the crawl supply. Alternatively, you’ll be able to add a sitemap or a file of URLs.
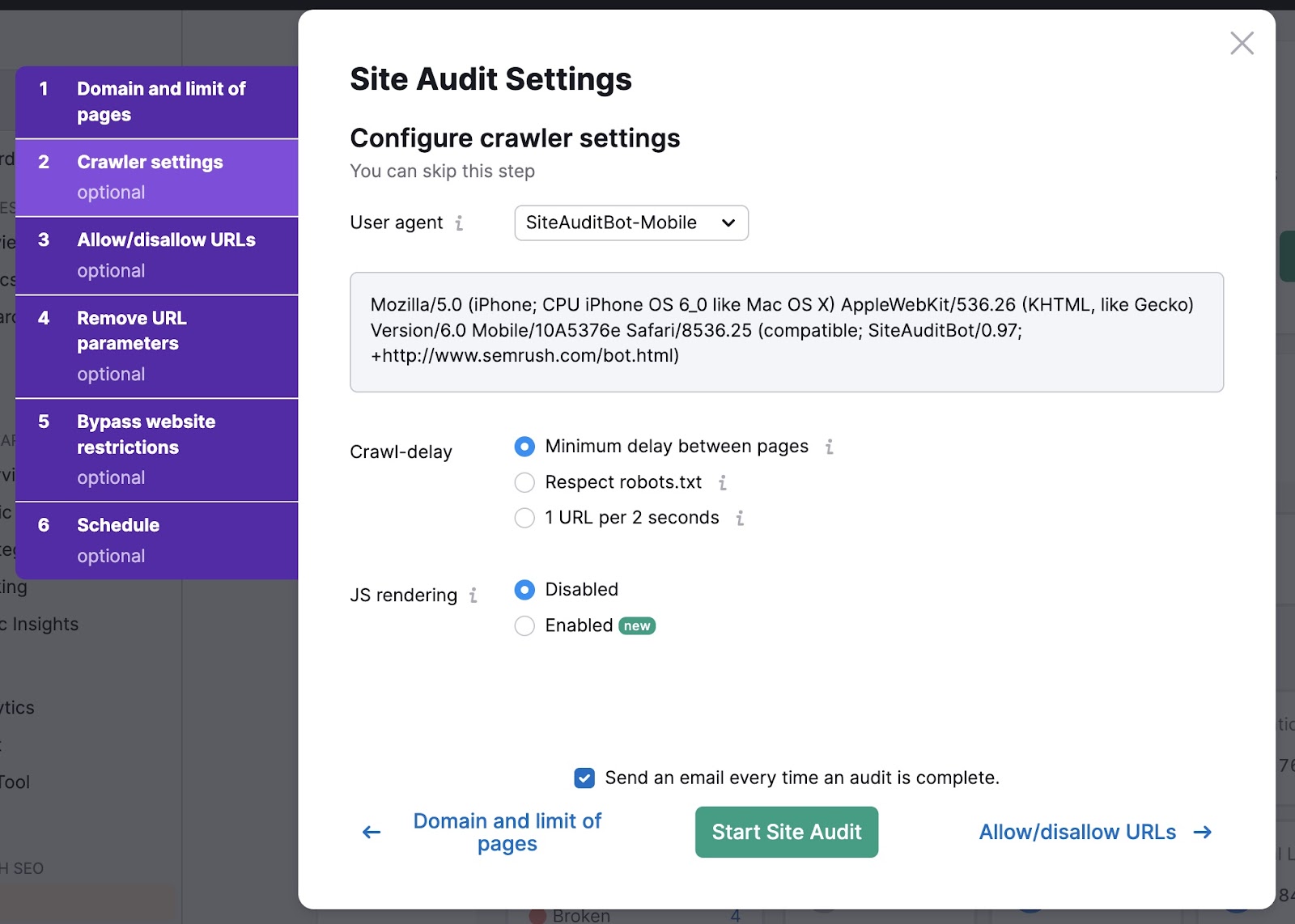
Within the “Crawler settings” tab, use the drop-down to pick a consumer agent. Select between GoogleBot and SiteAuditBot. And cell and desktop variations of every.
Then choose your crawl-delay settings. The “Minimal delay between pages” choice is normally really useful—it’s the quickest method to audit your web site.
Lastly, determine if you wish to allow JavaScript (JS) rendering. JavaScript rendering permits the crawler to see the identical content material your web site guests do.
This supplies extra correct outcomes however can take longer to finish.
Then, click on “Enable-disallow URLs.”
In order for you the crawler to solely verify sure URLs, you’ll be able to enter them right here. You can too disallow URLs to instruct the crawler to disregard them.
Subsequent, checklist URL parameters to inform the bots to disregard variations of the identical web page.
In case your web site remains to be underneath growth, you need to use “Bypass web site restrictions” settings to run an audit.
Lastly, schedule how typically you need the device to audit your web site. Common audits are a good suggestion to control your web site’s well being. And flag any crawlability points early on.
Verify the field to be notified by way of electronic mail as soon as the audit is full.
While you’re prepared, click on “Begin Web site Audit.”
The Web site Audit “Overview” report summarizes all the info the bots collected throughout the crawl. And provides you priceless details about your web site’s total well being.
The “Crawled Pages” widget tells you what number of pages the device crawled. And provides a breakdown of what number of pages are wholesome and what number of have points.
To get extra in-depth insights, navigate to the “Crawlability” part and click on “View particulars.”
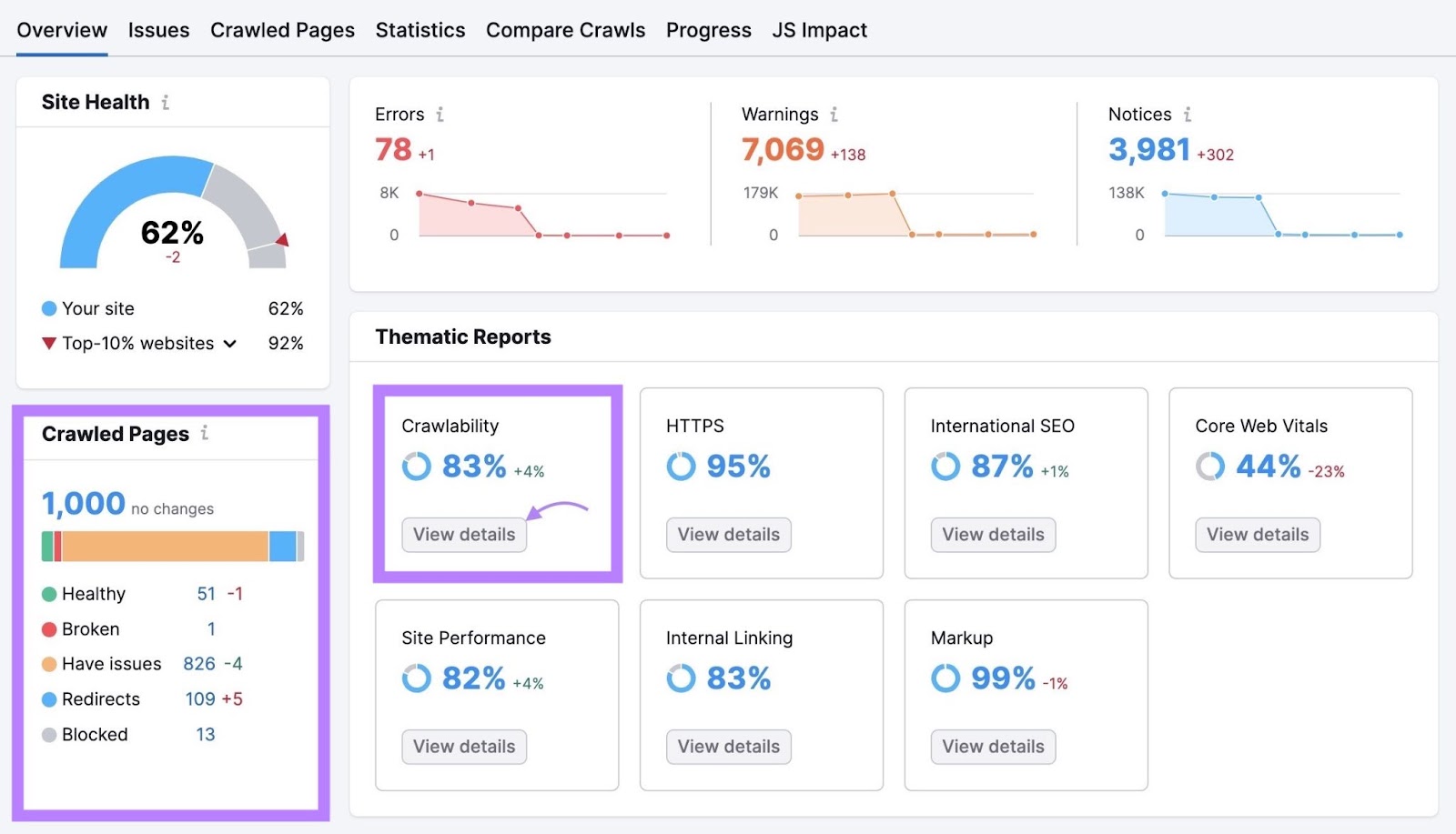
Right here, you’ll discover how a lot of your web site’s crawl funds was wasted and what points bought in the best way. Resembling short-term redirects, everlasting redirects, duplicate content material, and sluggish load velocity.
Clicking any of the bars will present you a listing of the pages with that difficulty.
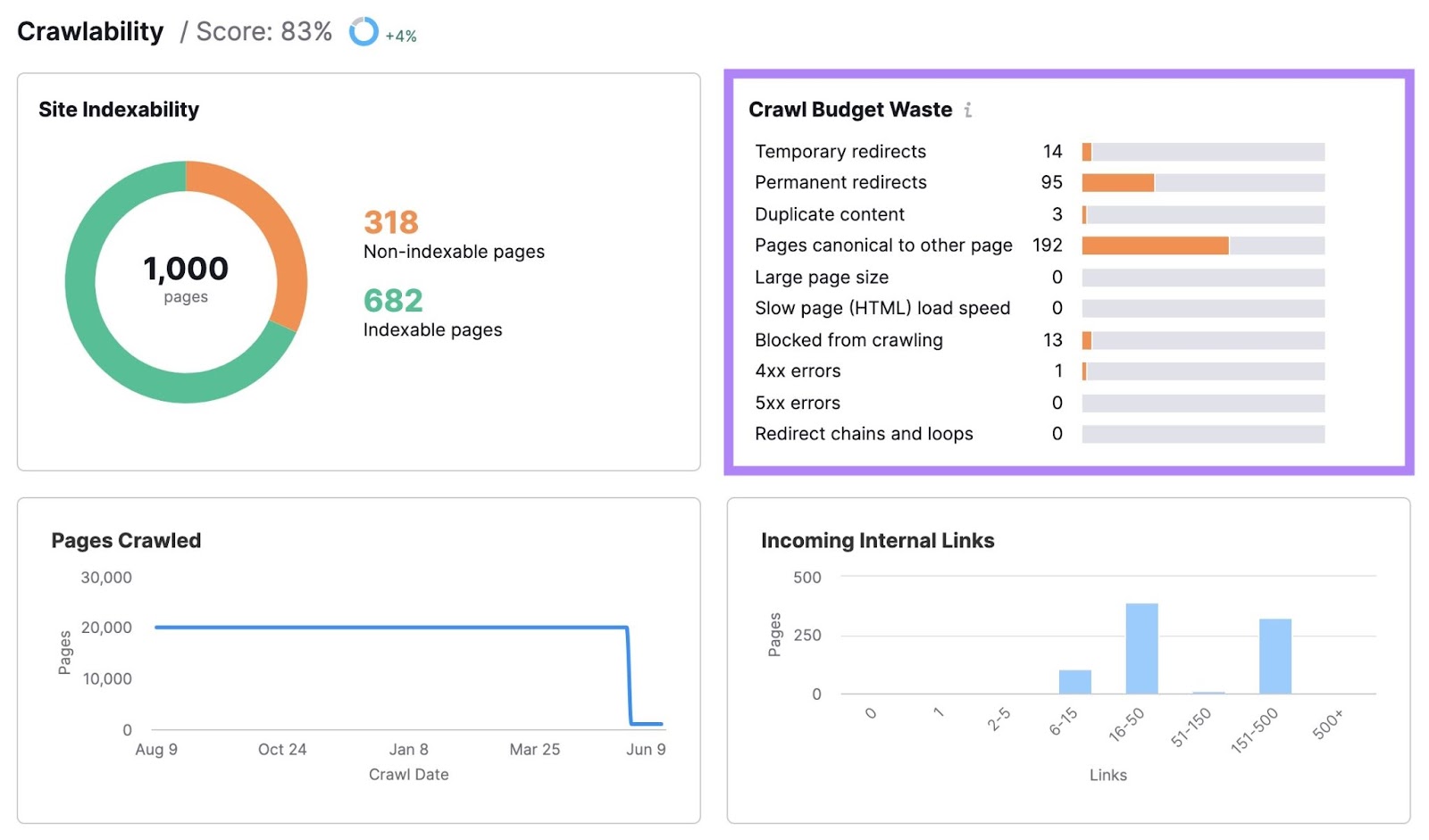
Relying on the problem, you’ll see info in numerous columns for every affected web page.
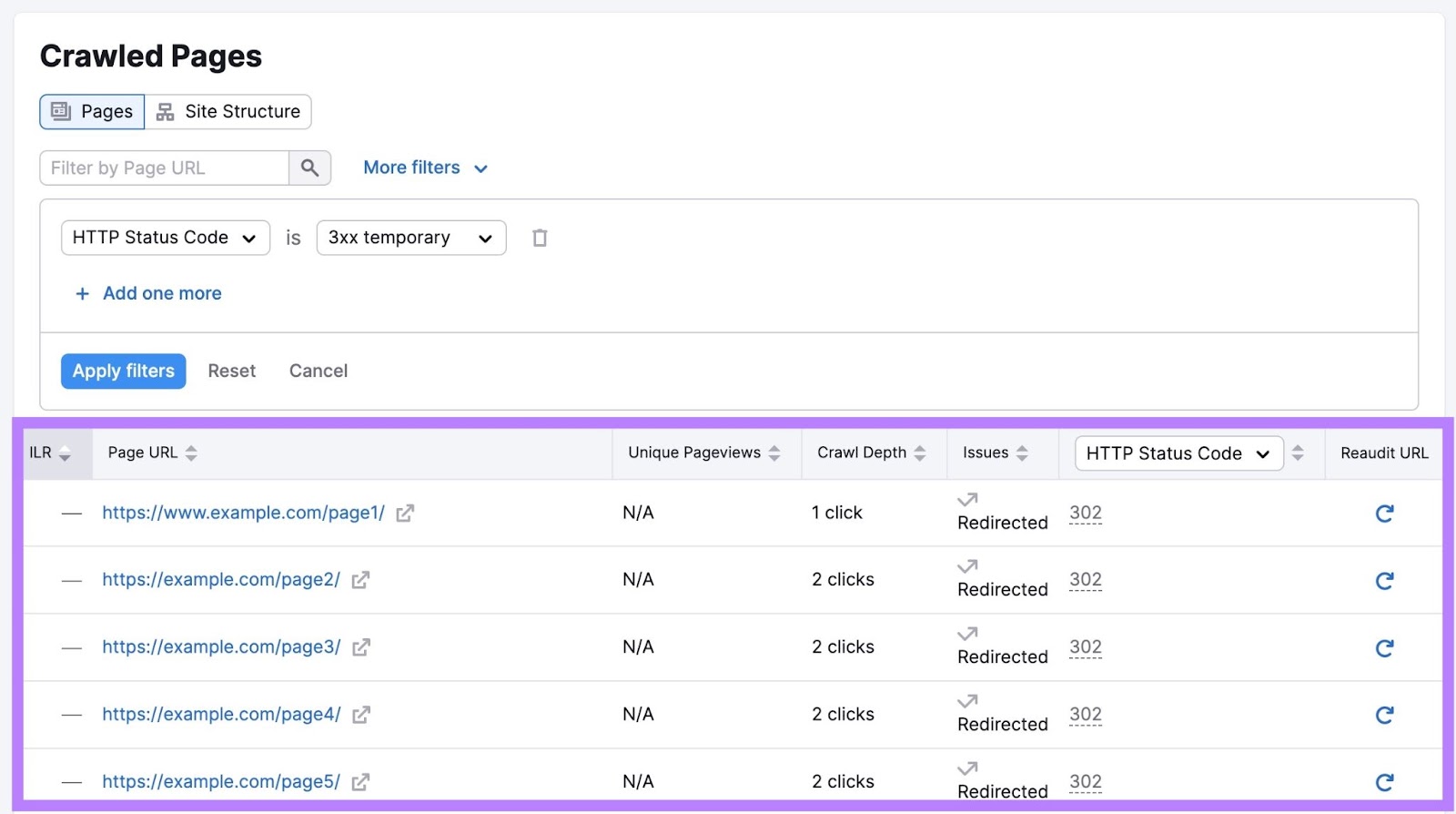
Undergo these pages and repair the corresponding points. To enhance your web site’s crawlability.
7 Suggestions for Crawl Finances Optimization
As soon as you understand the place your web site’s crawl funds points are, you’ll be able to repair them to maximise your crawl effectivity.
Listed below are among the foremost issues you are able to do:
1. Enhance Your Web site Pace
Enhancing your site speed can assist Google crawl your web site quicker. Which may result in higher use of your web site’s crawl funds. Plus, it’s good for the user experience (UX) and SEO.
To verify how briskly your pages load, head again to the Web site Audit venture you arrange earlier and click on “View particulars” within the “Web site Efficiency” field.
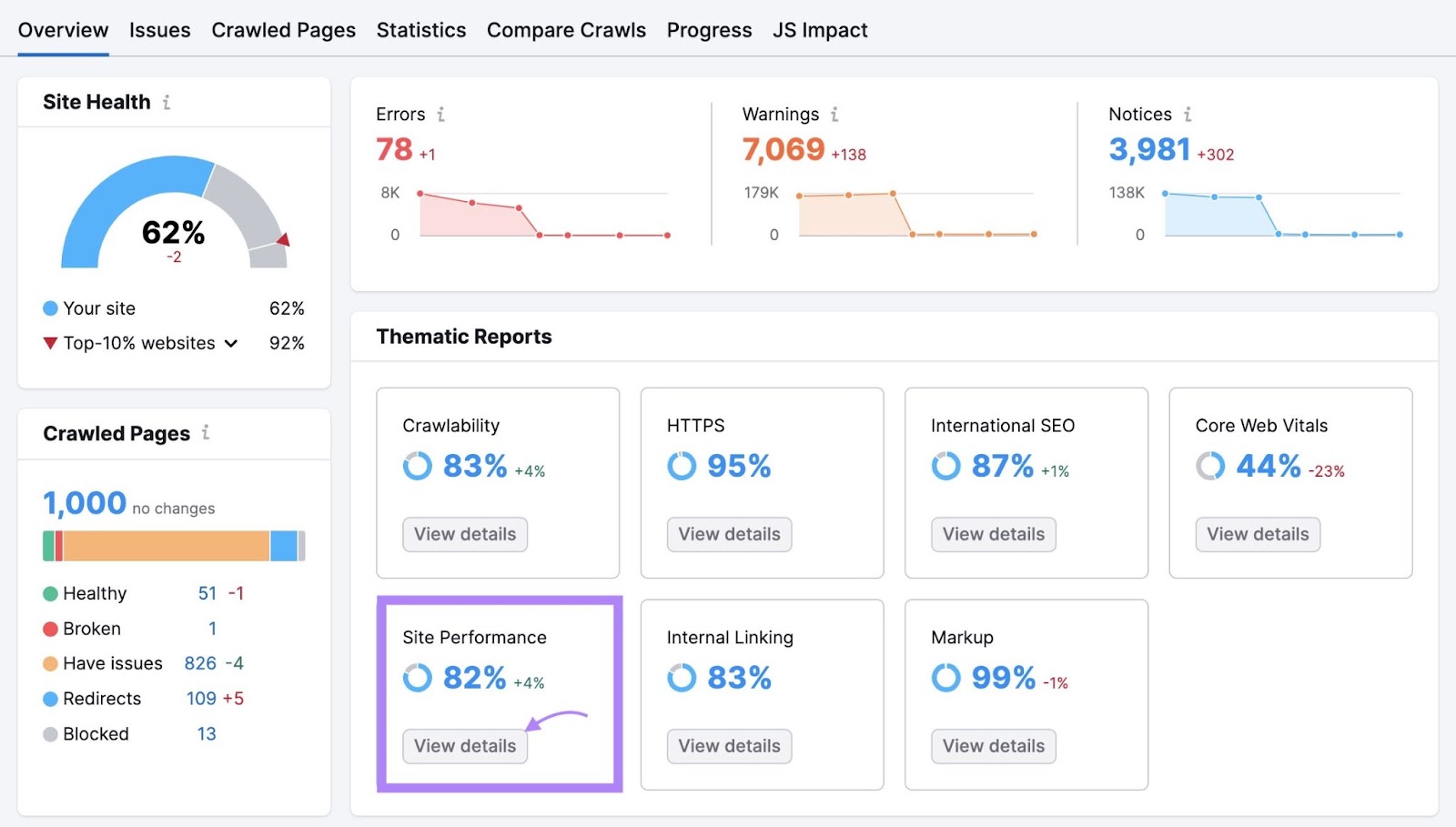
You’ll see a breakdown of how briskly your pages load and your common web page load velocity. Together with a listing of errors and warnings that could be resulting in poor efficiency.
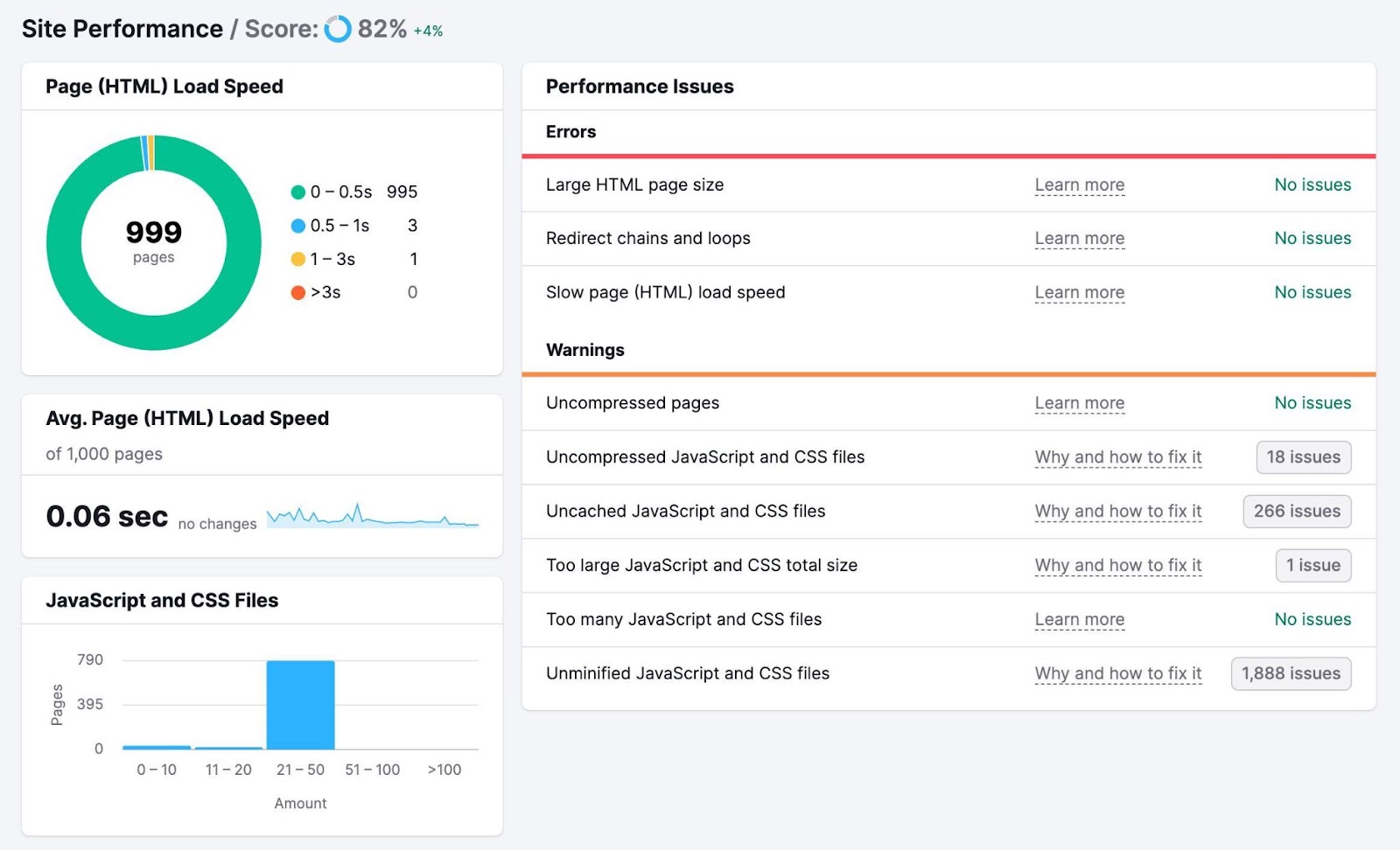
There are numerous methods to enhance your web page velocity, together with:
- Optimizing your images: Use on-line instruments like Image Compressor to scale back file sizes with out making your pictures blurry
- Minimizing your code and scripts: Think about using a web based device like Minifier.org or a WordPress plugin like WP Rocket to minify your web site’s code for quicker loading
- Utilizing a content material supply community (CDN): A CDN is a distributed community of servers that delivers net content material to customers based mostly on their location for quicker load speeds
2. Use Strategic Inside Linking
A sensible internal linking construction could make it simpler for search engine crawlers to search out and perceive your content material. Which may make for extra environment friendly use of your crawl funds and enhance your rating potential.
Think about your web site a hierarchy, with the homepage on the prime. Which then branches off into totally different classes and subcategories.
Every department ought to result in extra detailed pages or posts associated to the class they fall underneath.
This creates a transparent and logical construction on your web site that’s straightforward for customers and serps to navigate.
Add inside hyperlinks to all essential pages to make it simpler for Google to search out your most essential content material.
This additionally helps you keep away from orphaned pages—pages with no inside hyperlinks pointing to them. Google can nonetheless discover these pages, nevertheless it’s a lot simpler when you have related inside hyperlinks pointing to them.
Click on “View particulars” within the “Inside Linking” field of your Site Audit venture to search out points along with your inside linking.
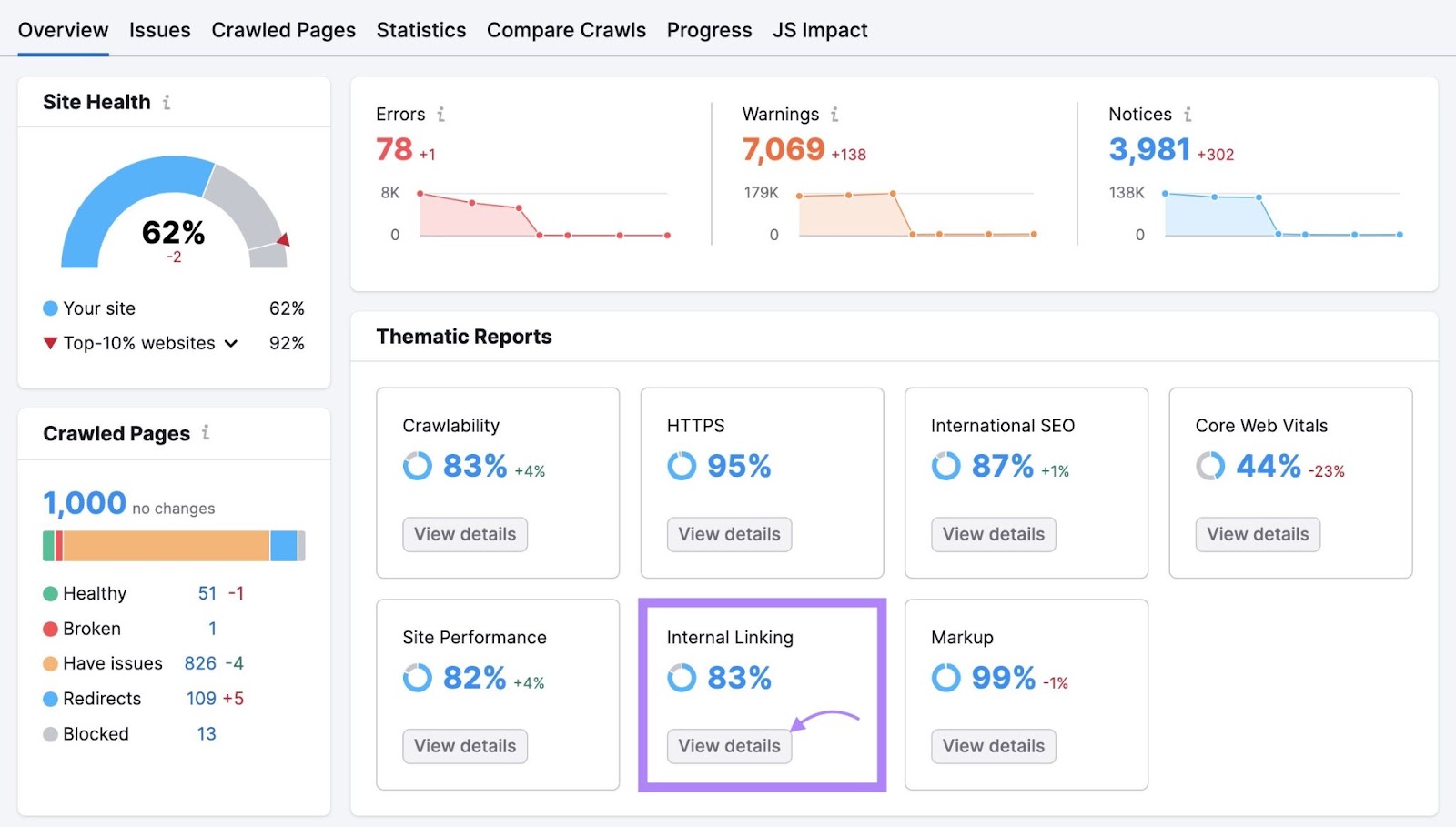
You’ll see an outline of your web site’s inside linking construction. Together with what number of clicks it takes to get to every of your pages out of your homepage.
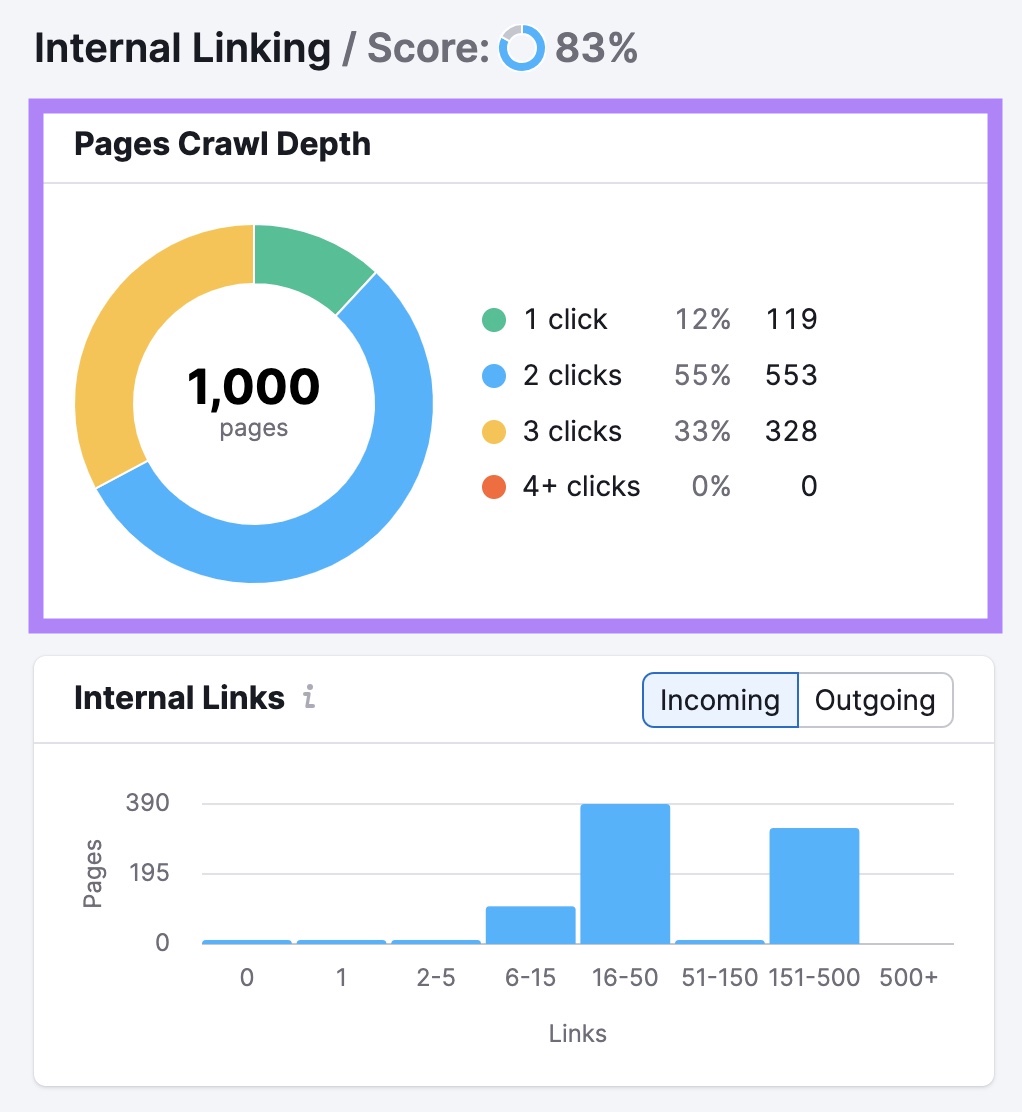
You’ll additionally see a listing of errors, warnings, and notices. These cowl points like broken links, nofollow attributes on inside hyperlinks, and hyperlinks with no anchor textual content.
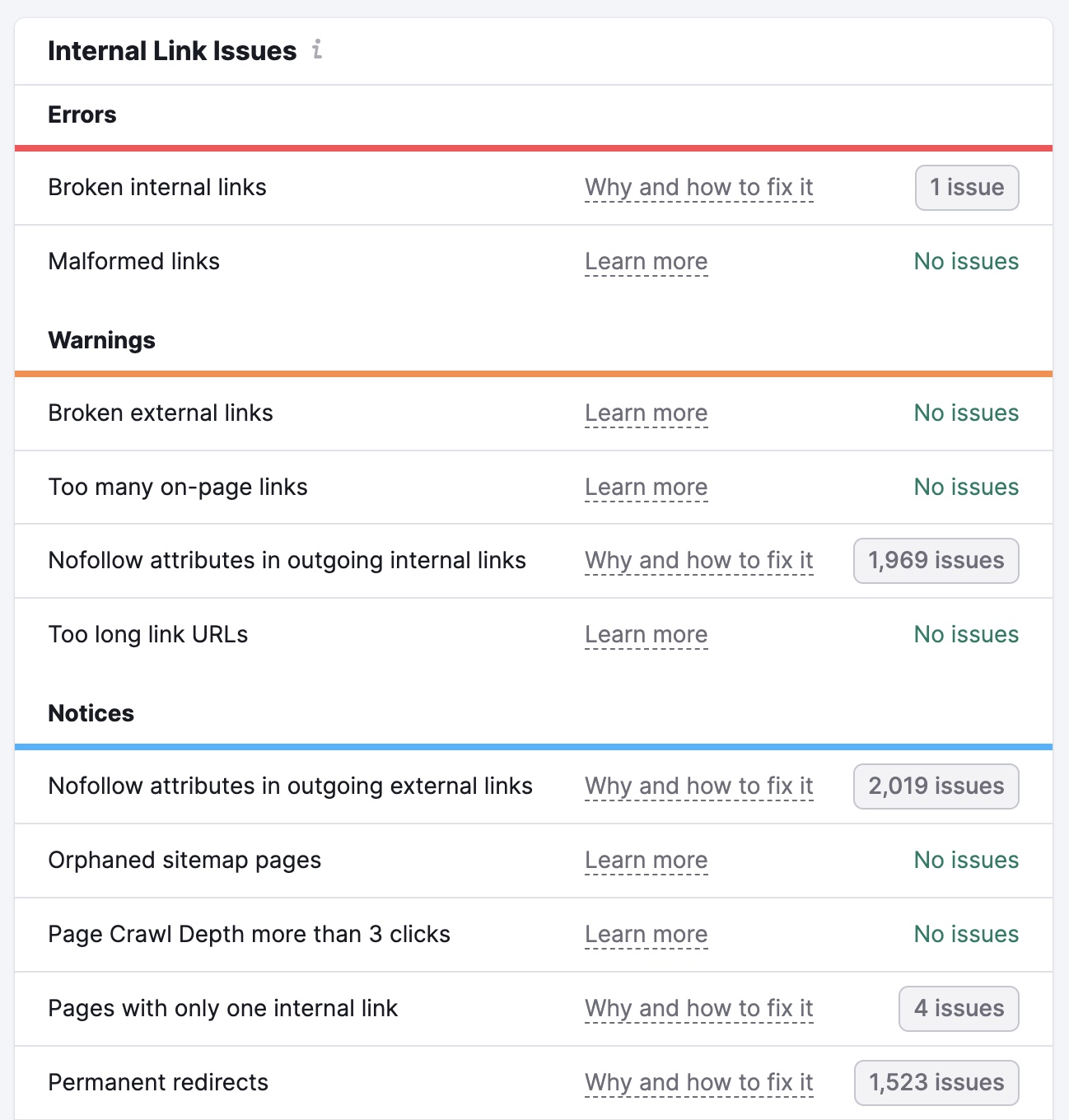
Undergo these and rectify the problems on every web page. To make it simpler for serps to crawl and index your content material.
3. Maintain Your Sitemap As much as Date
Having an up-to-date XML sitemap is one other approach you’ll be able to level Google towards your most essential pages. And updating your sitemap whenever you add new pages could make them extra prone to be crawled (however that’s not assured).
Your sitemap would possibly look one thing like this (it might range relying on the way you generate it):
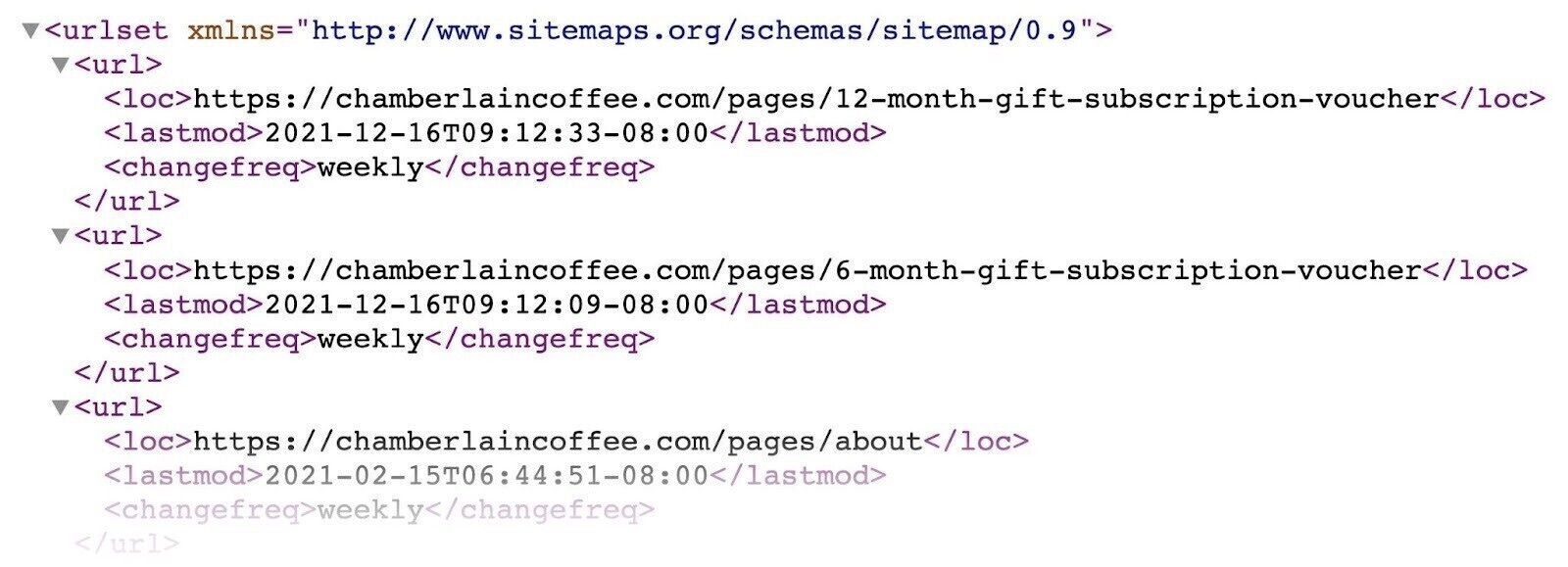
Google recommends solely together with URLs that you just wish to seem in search leads to your sitemap. To keep away from doubtlessly losing crawl funds (see the following tip for extra on that).
You can too use the
Additional studying: How to Submit a Sitemap to Google
4. Block URLs You Don’t Need Search Engines to Crawl
Use your robots.txt file (a file that tells search engine bots which pages ought to and shouldn’t be crawled) to reduce the possibilities of Google crawling pages you don’t need it to. This can assist cut back crawl funds waste.
Why would you wish to stop crawling for some pages?
As a result of some are unimportant or personal. And also you in all probability don’t need serps to crawl these pages and waste their assets.
Right here’s an instance of what a robots.txt file would possibly appear like:
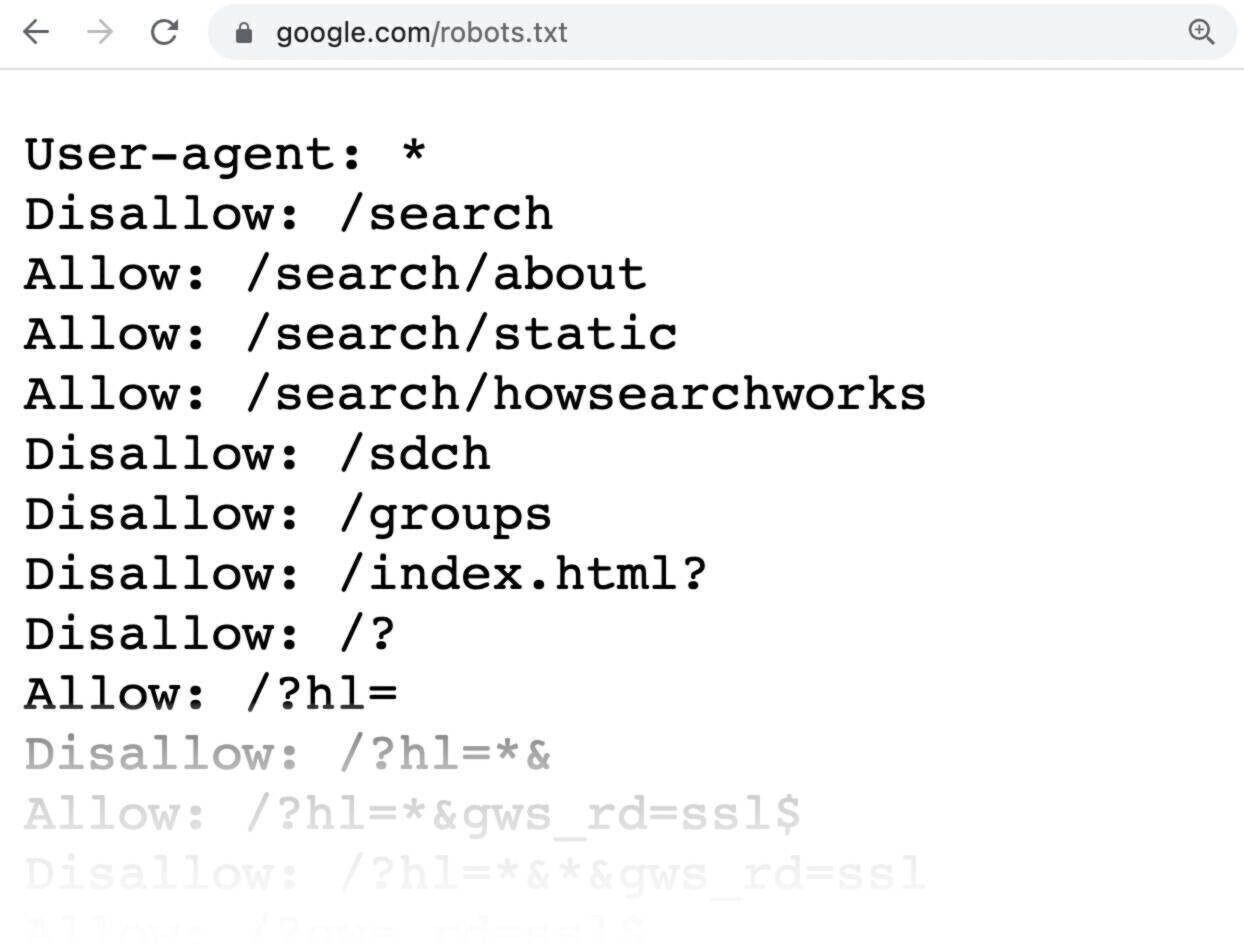
All pages after “Disallow:” specify the pages you don’t need serps to crawl.
For extra on the right way to create and use these recordsdata correctly, take a look at our guide to robots.txt.
5. Take away Pointless Redirects
Redirects take customers (and bots) from one URL to a different. And might decelerate web page load instances and waste crawl funds.
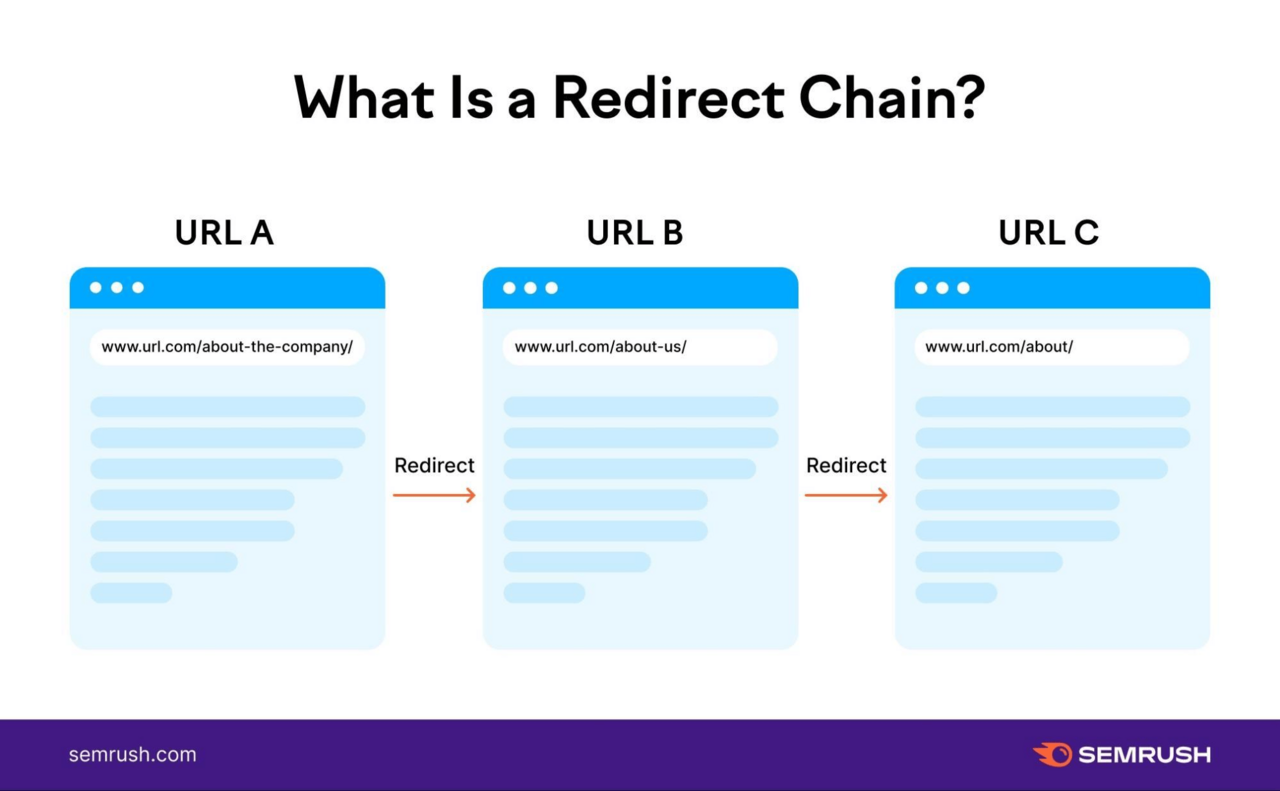
This may be significantly problematic when you have redirect chains. These happen when you’ve got multiple redirect between the unique URL and the ultimate URL.
Like this:
To study extra in regards to the redirects arrange in your web site, open the Site Audit device and navigate to the “Points” tab.
Enter “redirect” within the search bar to see points associated to your web site’s redirects.
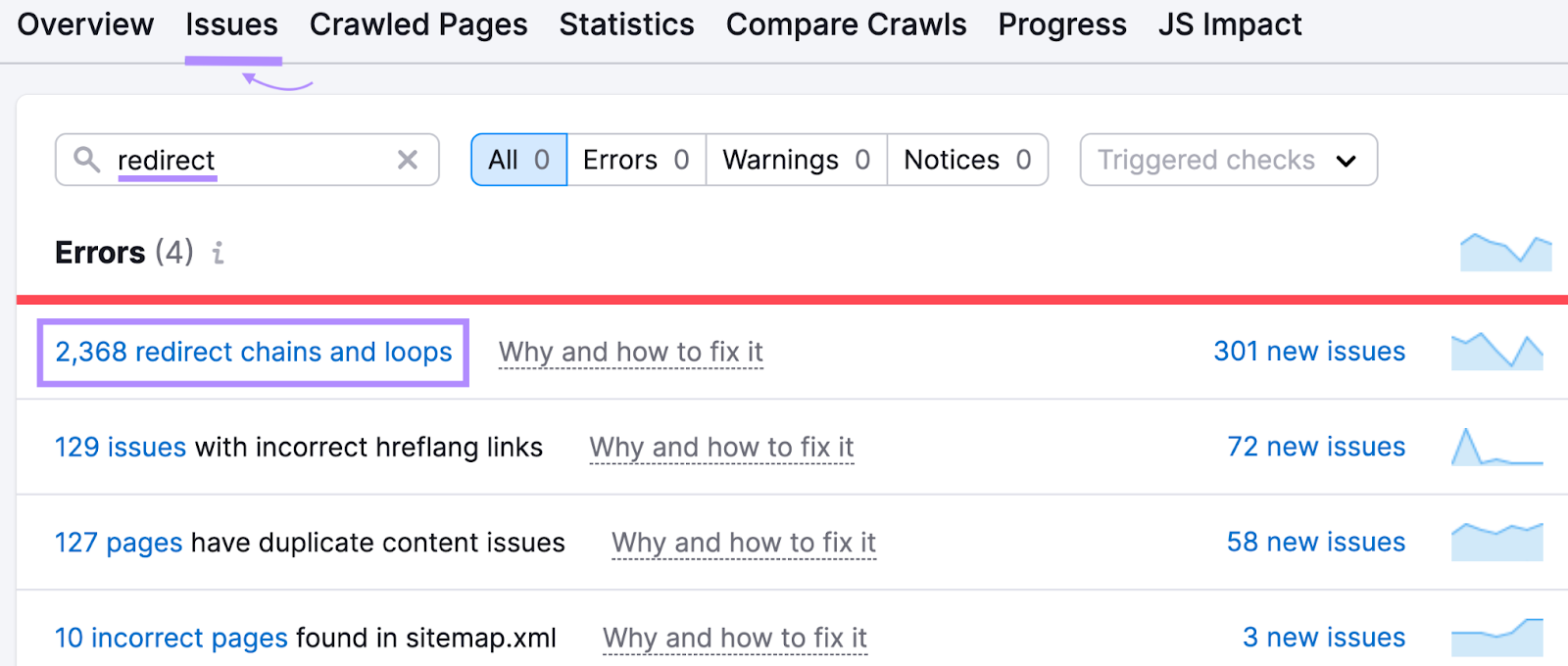
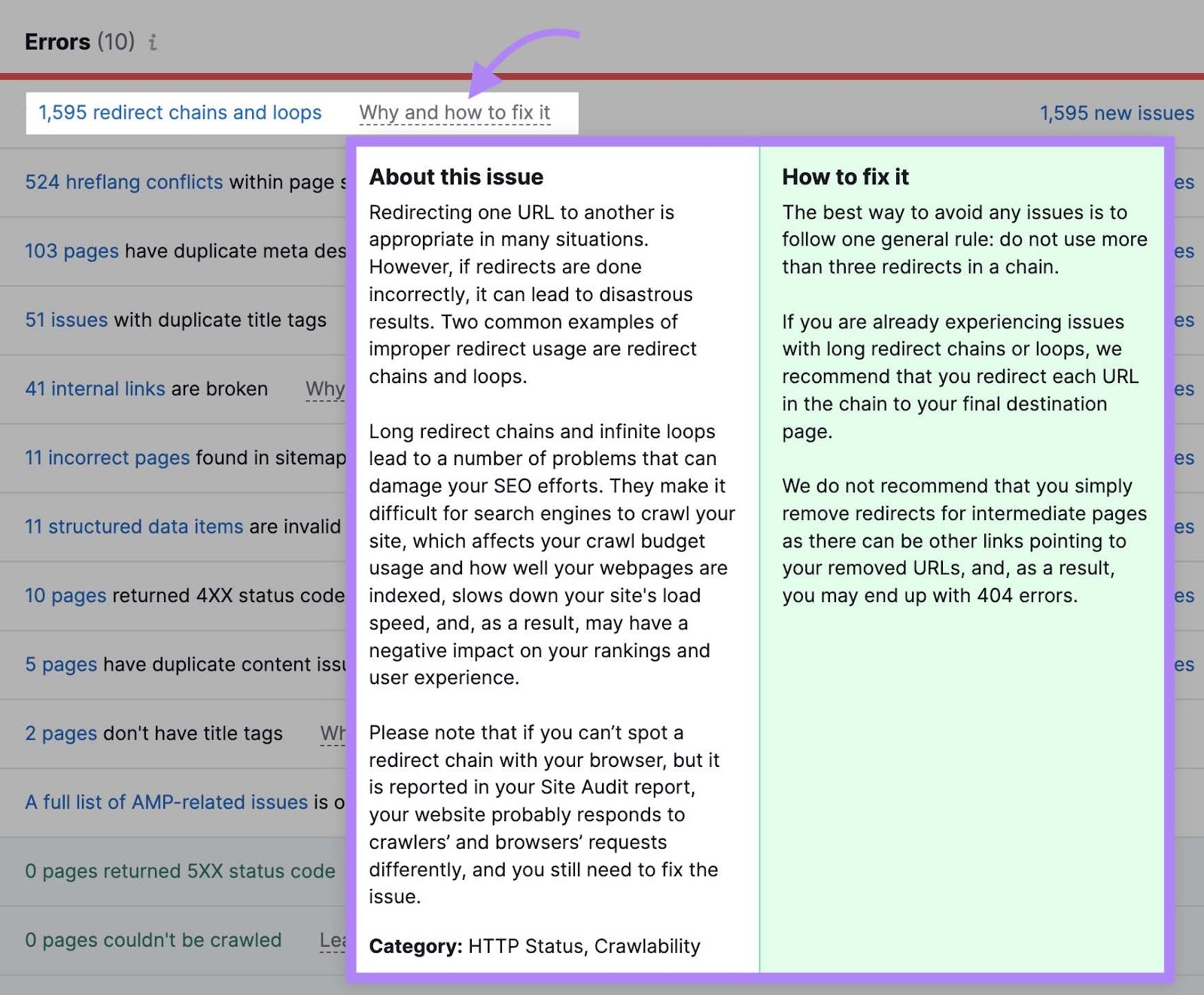
Click on “Why and the right way to repair it” or “Study extra” to get extra details about every difficulty. And to see steering on the right way to repair it.
6. Repair Damaged Hyperlinks
Damaged hyperlinks are people who don’t result in dwell pages—they normally return a 404 error code as a substitute.
This isn’t essentially a foul factor. Actually, pages that don’t exist ought to sometimes return a 404 standing code.
However having plenty of hyperlinks pointing to damaged pages that don’t exist wastes crawl funds. As a result of bots should still attempt to crawl it, although there may be nothing of worth on the web page. And it’s irritating for customers who observe these hyperlinks.
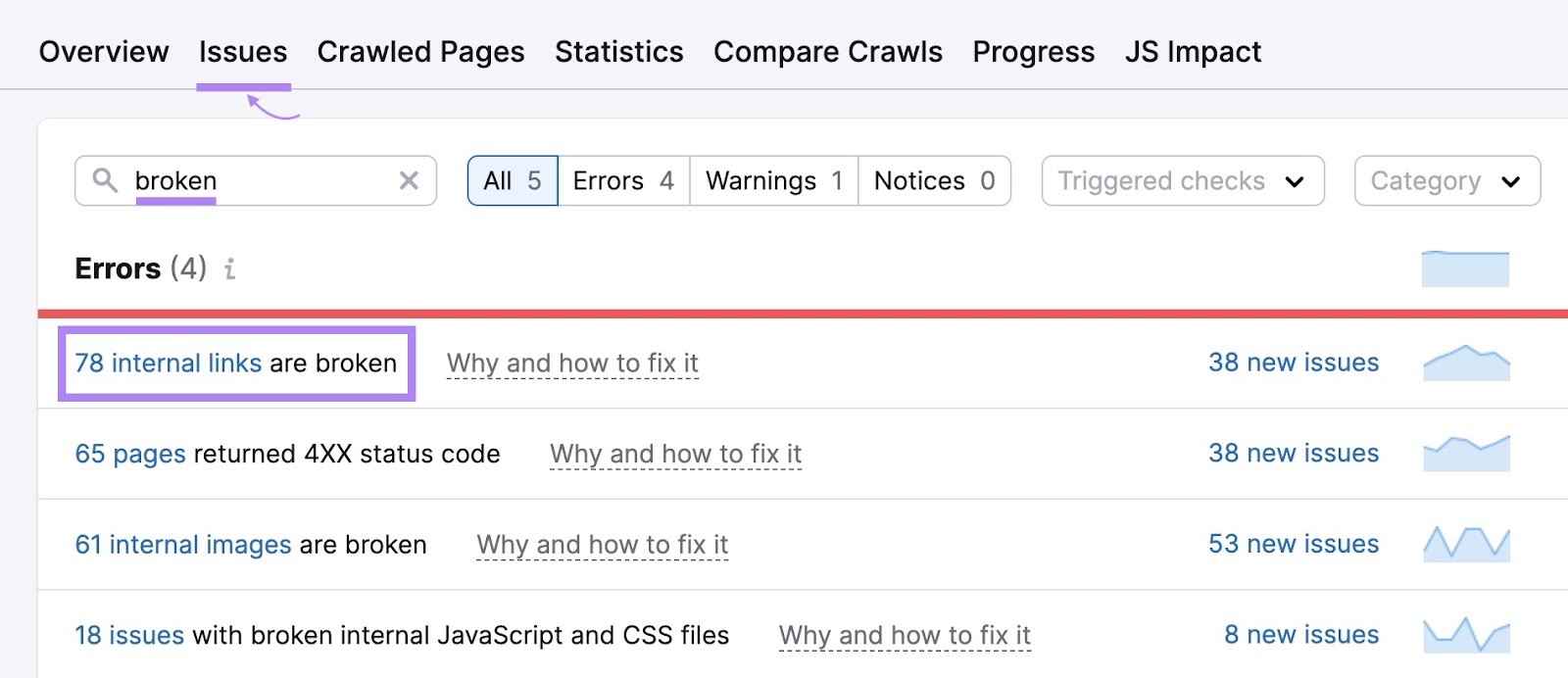
To establish damaged hyperlinks in your web site, go to the “Points” tab in Site Audit and enter “damaged” within the search bar.
Search for the “# inside hyperlinks are damaged” error. If you happen to see it, click on the blue hyperlink over the quantity to see extra particulars.
You’ll then see a listing of your pages with damaged hyperlinks. Together with the particular hyperlink on every web page that’s damaged.
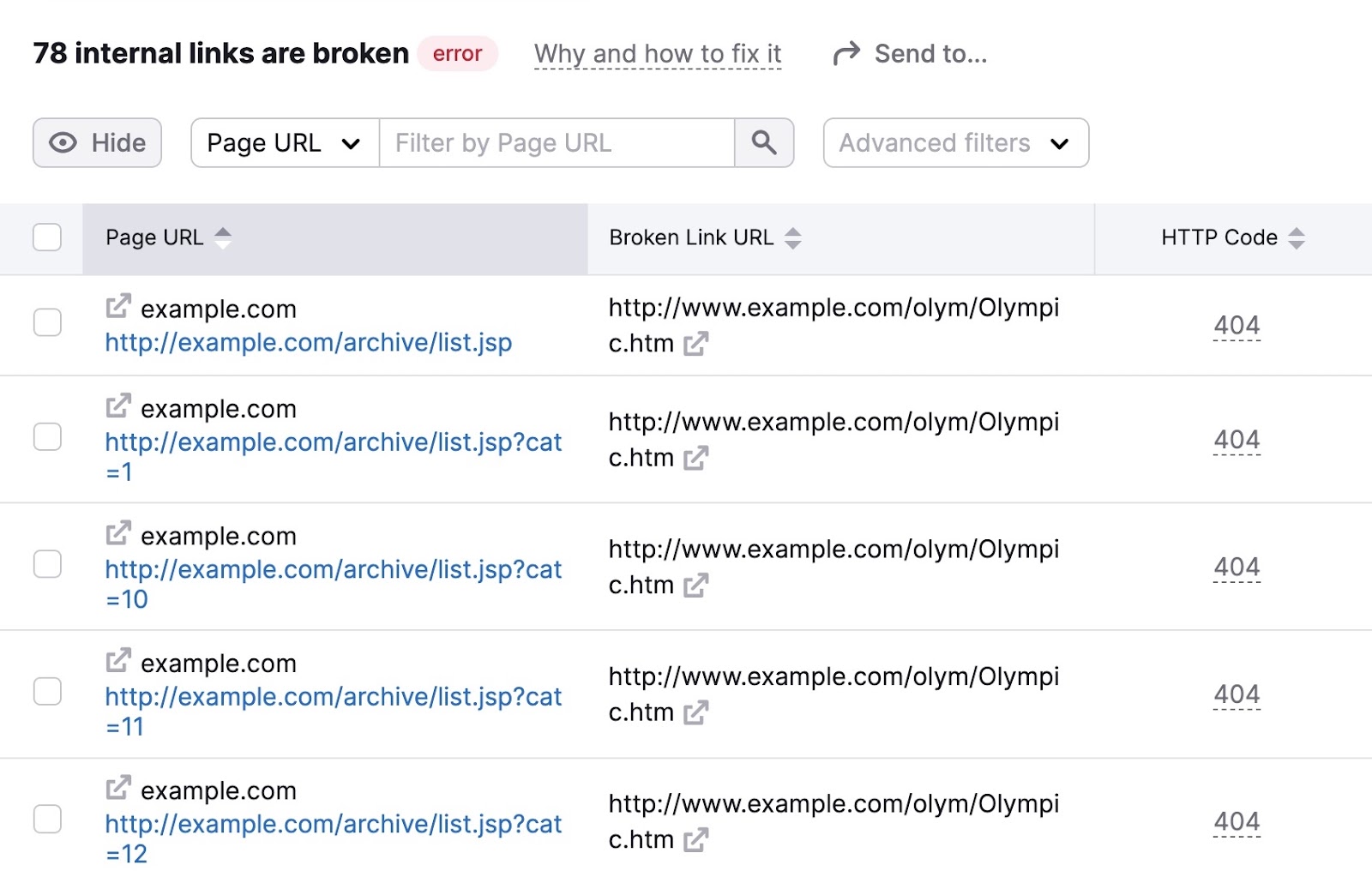
Undergo these pages and repair the damaged hyperlinks to enhance your web site’s crawlability.
7. Remove Duplicate Content material
Duplicate content is when you’ve got extremely related pages in your web site. And this difficulty can waste crawl funds as a result of bots are primarily crawling a number of variations of the identical web page.
Duplicate content material can are available in just a few types. Resembling equivalent or practically equivalent pages (you usually wish to keep away from this). Or variations of pages attributable to URL parameters (frequent on ecommerce web sites).
Go to the “Points” tab inside Site Audit to see whether or not there are any duplicate content material issues in your web site.
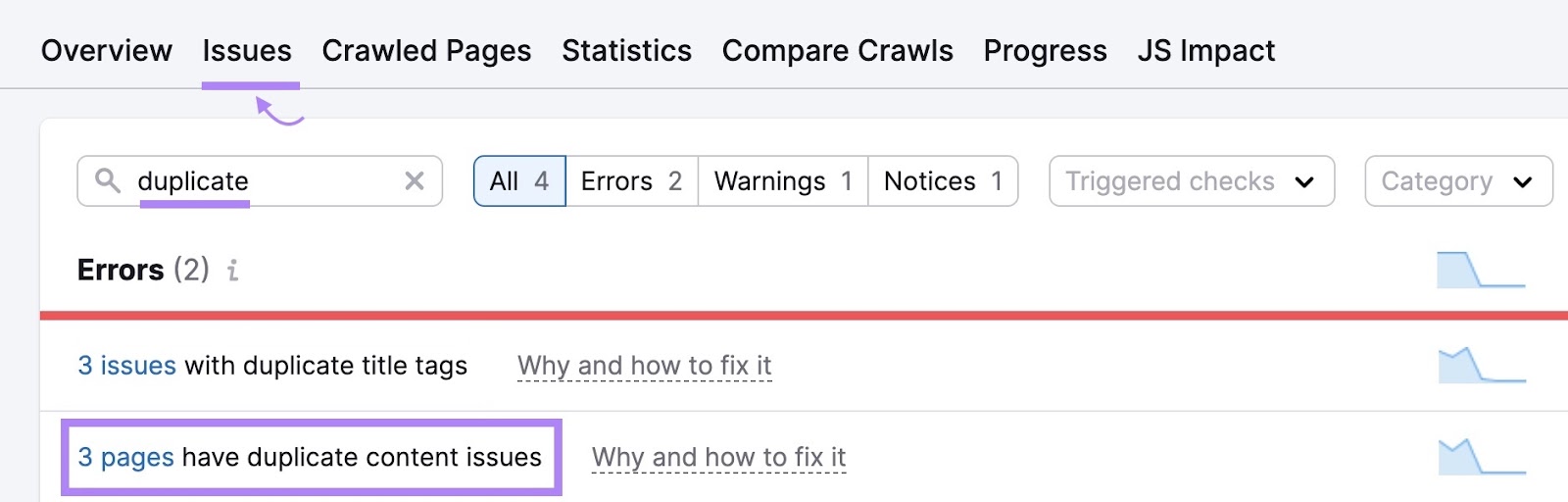
If there are, contemplate these choices:
- Use “rel=canonical” tags within the HTML code to inform Google which web page you wish to flip up in search outcomes
- Select one web page to function the principle web page (make sure that so as to add something the extras embrace that’s lacking in the principle one). Then, use 301 redirects to redirect the duplicates.
Maximize Your Crawl Finances with Common Web site Audits
Frequently monitoring and optimizing technical elements of your web site helps net crawlers discover your content material.
And since serps want to search out your content material with a view to rank it in search outcomes, that is vital.
Use Semrush’s Site Audit device to measure your web site’s well being and spot errors earlier than they trigger efficiency points.


